TF_LIST = ["Nanog", "Klf4", "Oct4", "Sox2"]
#TF_LIST = ["Nanog"]
INPUT_DIR = "/home/philipp/BPNet/input/"
BATCH_SIZE = 64
MAX_EPOCHS = 100
EARLY_STOP_PATIENCE = 4
RESTORE_BEST_WEIGHTS = True
plot_while_train = False03 Training and Metrics
Training BPNet to predict the ChIP-Nexus profiles and total counts for all four TFs.
1 Train Parameters
2 Libraries
import matplotlib.pyplot as plt
import numpy as np
plt.style.use('dark_background')
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from src.architectures import BPNet
from src.utils import ChIP_Nexus_Dataset, dummy_shape_predictions, dummy_total_counts_predictions
from src.loss import neg_log_multinomial
from src.metrics import permute_array, bin_max_values, bin_counts_amb, binary_labels_from_counts, compute_auprc_bins
color_pal = {"Oct4": "#CD5C5C", "Sox2": "#849EEB", "Nanog": "#FFE03F", "Klf4": "#92C592", "patchcap": "#827F81"}
import pandas as pd
import sklearn.metrics as skm
import seaborn as snsdevice = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")Using cuda device3 Data
train_dataset = ChIP_Nexus_Dataset(set_name="train",
input_dir=INPUT_DIR,
TF_list=TF_LIST)
train_datasetChIP_Nexus_Dataset
Set: train
TFs: ['Nanog', 'Klf4', 'Oct4', 'Sox2']
Size: 93904Determine \(\lambda\) hyperparameter to weight between the negative multinomial log-likelihood for the shape prediction and the mean squared error for the total count prediction.
lambda_param = (np.median(train_dataset.tf_counts.sum(axis=-1), axis=0)).mean() / 2
lambda_param58.6875dummy_shape_predictions(train_dataset)Unfiform Prediction Loss: 490.46
Mean Prediction Loss: 438.73
Perfect Prediction Loss: 133.78dummy_total_counts_predictions(train_dataset)Mean Prediction Loss: 0.71
Perfect Prediction Loss: 0.00tune_dataset = ChIP_Nexus_Dataset(set_name="tune",
input_dir=INPUT_DIR,
TF_list=TF_LIST)
tune_datasetChIP_Nexus_Dataset
Set: tune
TFs: ['Nanog', 'Klf4', 'Oct4', 'Sox2']
Size: 29277dummy_shape_predictions(tune_dataset)Unfiform Prediction Loss: 494.43
Mean Prediction Loss: 442.46
Perfect Prediction Loss: 135.56test_dataset = ChIP_Nexus_Dataset(set_name="test",
input_dir=INPUT_DIR,
TF_list=TF_LIST)
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=0, pin_memory=True)
test_datasetChIP_Nexus_Dataset
Set: test
TFs: ['Nanog', 'Klf4', 'Oct4', 'Sox2']
Size: 27727dummy_shape_predictions(test_dataset)Unfiform Prediction Loss: 513.48
Mean Prediction Loss: 460.98
Perfect Prediction Loss: 139.21dummy_total_counts_predictions(test_dataset)Mean Prediction Loss: 0.70
Perfect Prediction Loss: 0.004 Shape Prediction
4.1 Train Loop
model = BPNet(n_dil_layers=9, TF_list=TF_LIST, pred_total=False, bias_track=True).to(device)
optimizer = optim.Adam(model.parameters(), lr=4*1e-4)
train_loader=DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=0, pin_memory=True)
tune_loader=DataLoader(tune_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=0, pin_memory=True)
train_loss, test_loss = [], []
patience_counter = 0
for epoch in range(MAX_EPOCHS):
# test
test_loss_epoch = []
with torch.no_grad():
for one_hot, tf_counts, ctrl_counts, ctrl_smooth in tune_loader:
one_hot, tf_counts, ctrl_counts, ctrl_smooth = one_hot.to(device), tf_counts.to(device), ctrl_counts.to(device), ctrl_smooth.to(device)
profile_pred = model.forward(sequence=one_hot, bias_raw=ctrl_counts, bias_smooth=ctrl_smooth)
loss = neg_log_multinomial(k_obs=tf_counts, p_pred=profile_pred, device=device)
test_loss_epoch.append(loss.item())
test_loss.append(sum(test_loss_epoch)/len(test_loss_epoch))
# train
model.train()
train_loss_epoch = []
for one_hot, tf_counts, ctrl_counts, ctrl_smooth in train_loader:
one_hot, tf_counts, ctrl_counts, ctrl_smooth = one_hot.to(device), tf_counts.to(device), ctrl_counts.to(device), ctrl_smooth.to(device)
optimizer.zero_grad()
profile_pred = model.forward(sequence=one_hot, bias_raw=ctrl_counts, bias_smooth=ctrl_smooth)
loss = neg_log_multinomial(k_obs=tf_counts, p_pred=profile_pred, device=device)
train_loss_epoch.append(loss.item())
loss.backward()
optimizer.step()
train_loss.append(sum(train_loss_epoch)/len(train_loss_epoch))
if test_loss[-1] > np.array(test_loss).min():
patience_counter += 1
else:
patience_counter = 0
best_state_dict = model.state_dict()
if patience_counter == EARLY_STOP_PATIENCE:
break
if RESTORE_BEST_WEIGHTS:
model.load_state_dict(best_state_dict)4.2 Train and Tune Loss
df = pd.DataFrame({"epoch": np.arange(1, epoch+2), "train": train_loss, "test": test_loss})
df.to_csv("/home/philipp/BPNet/out/shape_loss.csv")
plt.plot(np.arange(epoch+1), np.array(train_loss), label="train")
plt.plot(np.arange(epoch+1), np.array(test_loss), label="test")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.show()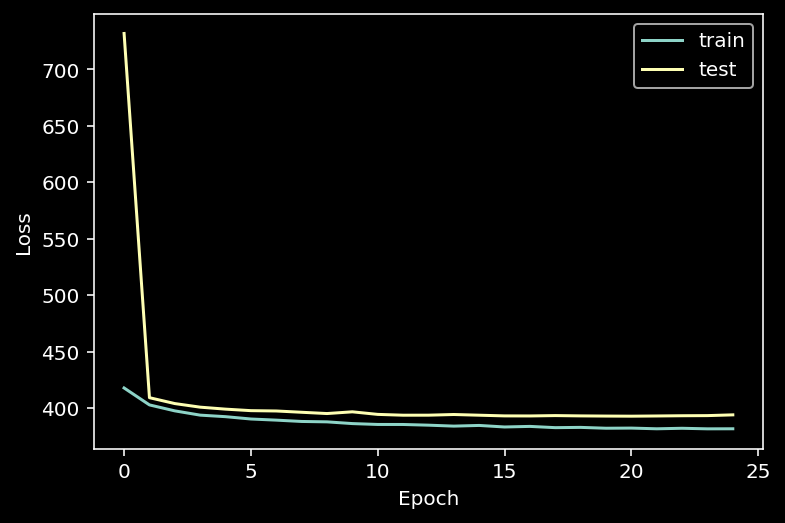
4.3 Save Model
torch.save(obj=model, f="/home/philipp/BPNet/trained_models/all_tfs_shape_model.pt")4.4 Evaluation
model = torch.load("/home/philipp/BPNet/trained_models/all_tfs_shape_model.pt")4.4.1 Check Examples
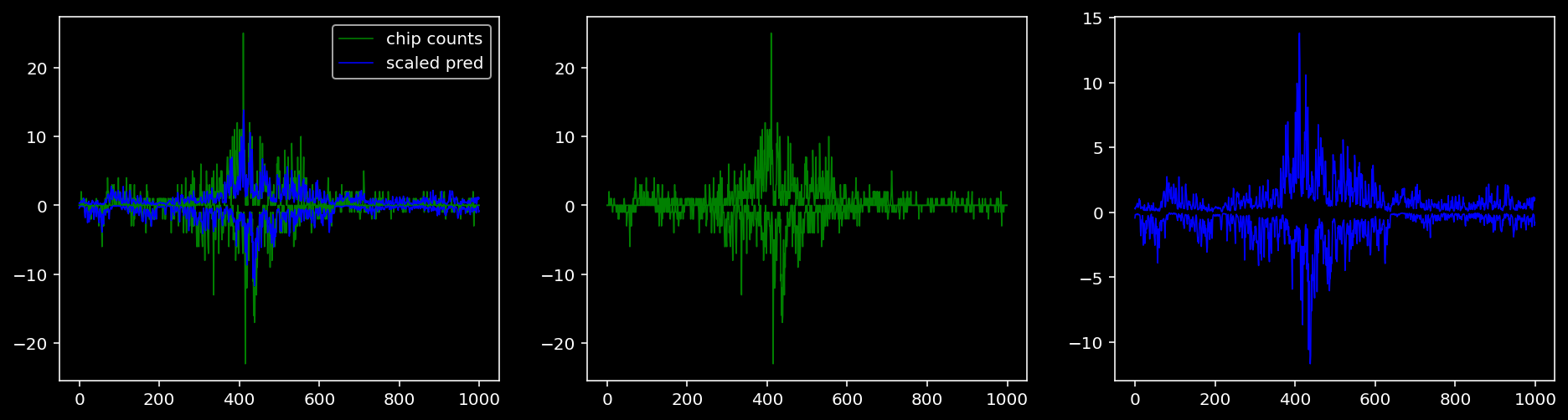
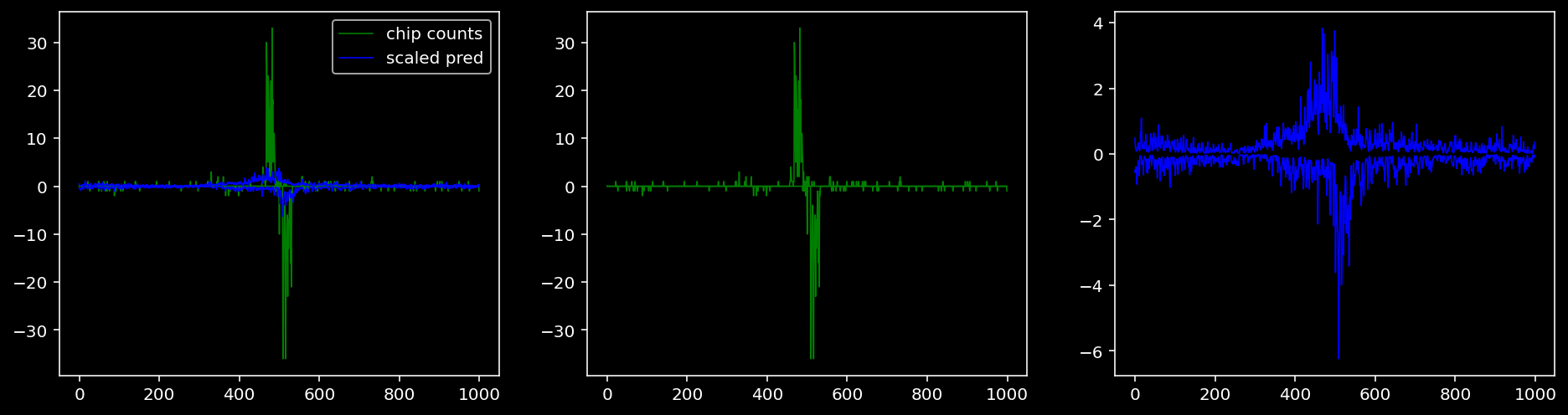
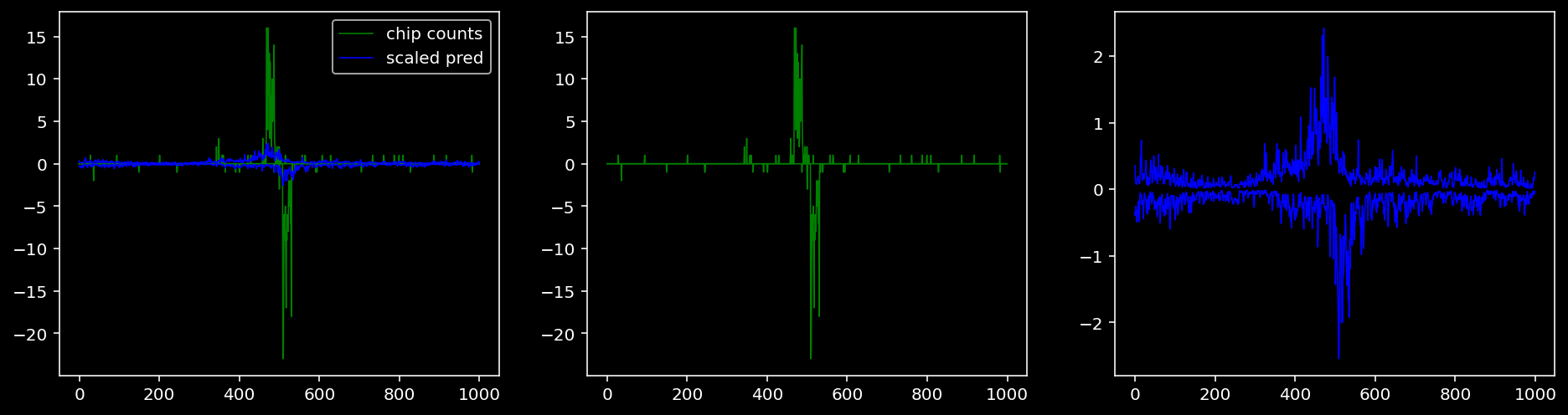
Plotting the real counts and the predictions for the first batch from the tune dataset.
tune_loader=DataLoader(tune_dataset, batch_size=10, shuffle=False, num_workers=0, pin_memory=True)
one_hot, tf_counts, ctrl_counts, ctrl_smooth = next(tune_loader.__iter__())
one_hot, tf_counts, ctrl_counts, ctrl_smooth = one_hot.to(device), tf_counts.to(device), ctrl_counts.to(device), ctrl_smooth.to(device)
profile_pred = model.forward(sequence=one_hot, bias_raw=ctrl_counts, bias_smooth=ctrl_smooth).to("cpu").detach().numpy()
tf_counts = tf_counts.to("cpu").detach().numpy()
scaled_pred = profile_pred * tf_counts.sum(axis=-1)[:,:,:,None]
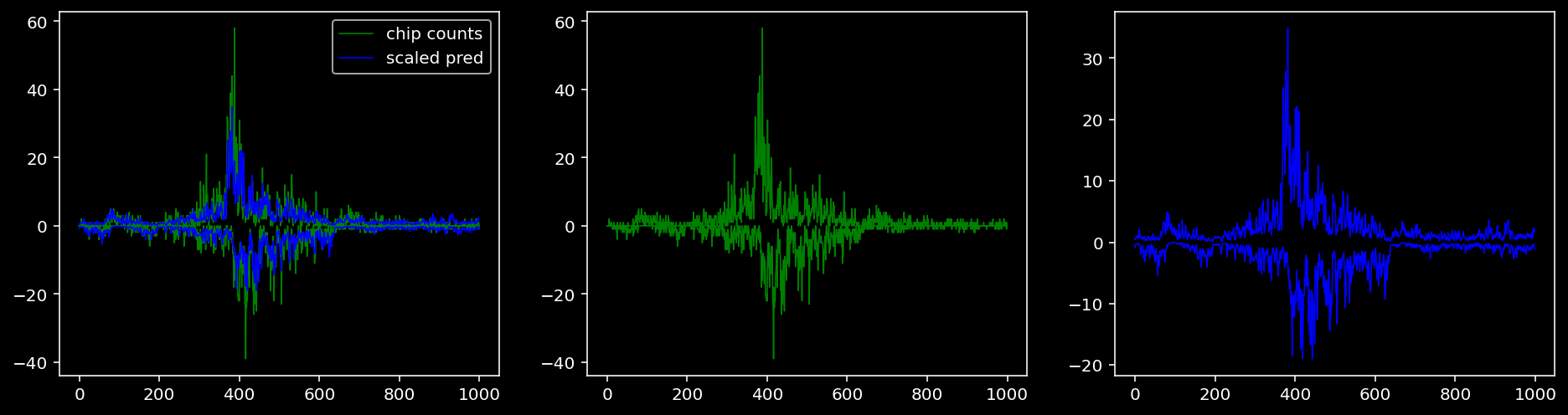
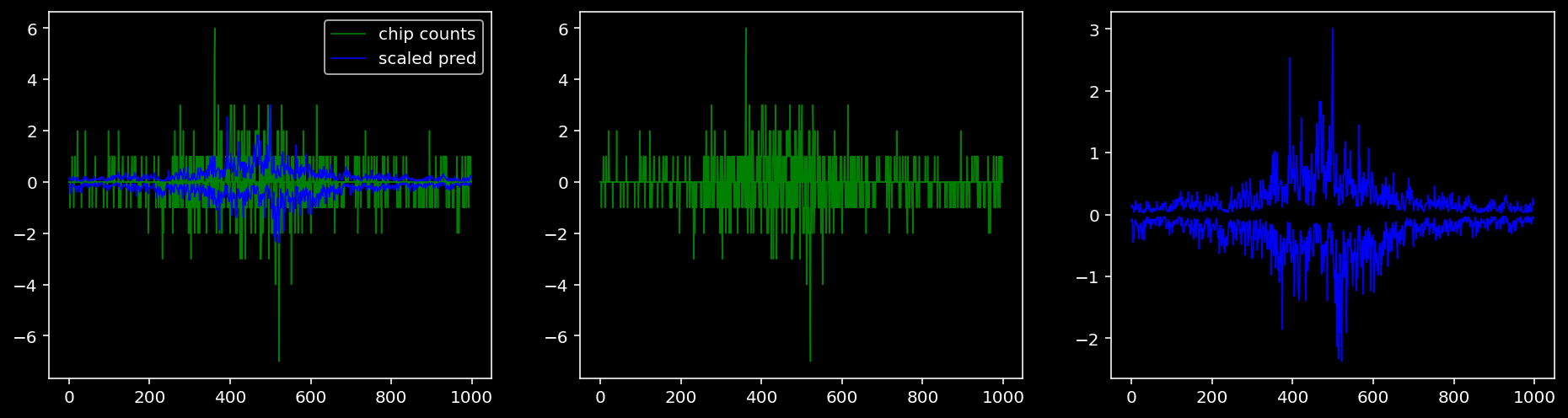
lw = 0.84.4.1.1 Nanog
tf = 0
for i in range(profile_pred.shape[0]):
fig, axis = plt.subplots(1, 3, figsize=(16, 4))
axis[0].plot(tf_counts[i, tf, 0], label="chip counts", color="green", linewidth=lw)
axis[0].plot(-tf_counts[i, tf, 1], color="green", linewidth=lw)
axis[1].plot(tf_counts[i, tf, 0], label="chip counts", color="green", linewidth=lw)
axis[1].plot(-tf_counts[i, tf, 1], color="green", linewidth=lw)
axis[0].plot(scaled_pred[i, tf, 0], label="scaled pred", color="blue", linewidth=lw)
axis[0].plot(-scaled_pred[i, tf, 1], color="blue", linewidth=lw)
axis[2].plot(scaled_pred[i, tf, 0], label="scaled pred", color="blue", linewidth=lw)
axis[2].plot(-scaled_pred[i, tf, 1], color="blue", linewidth=lw)
axis[0].legend()
plt.show()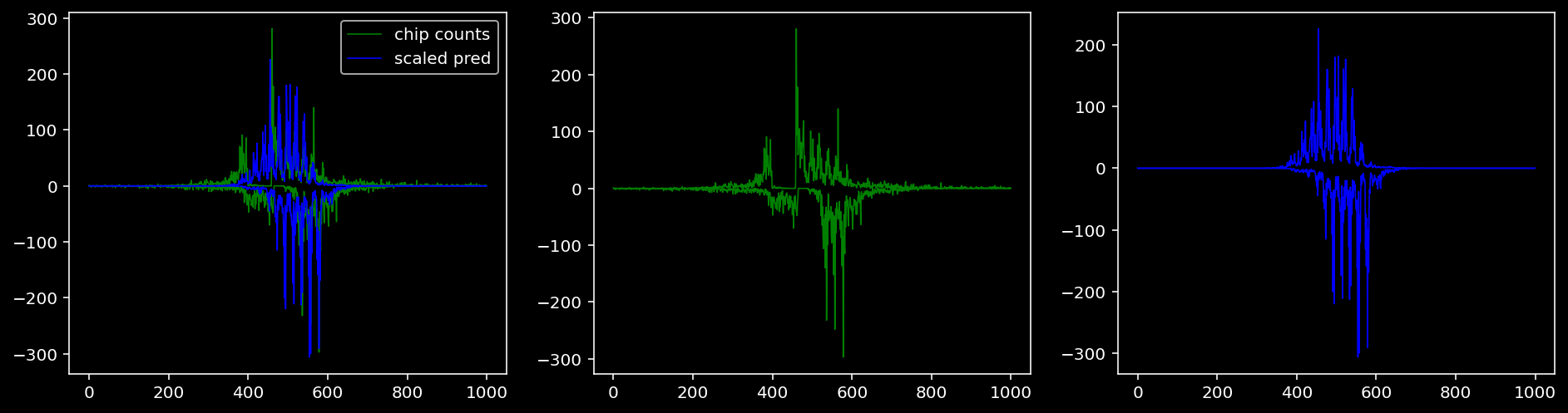
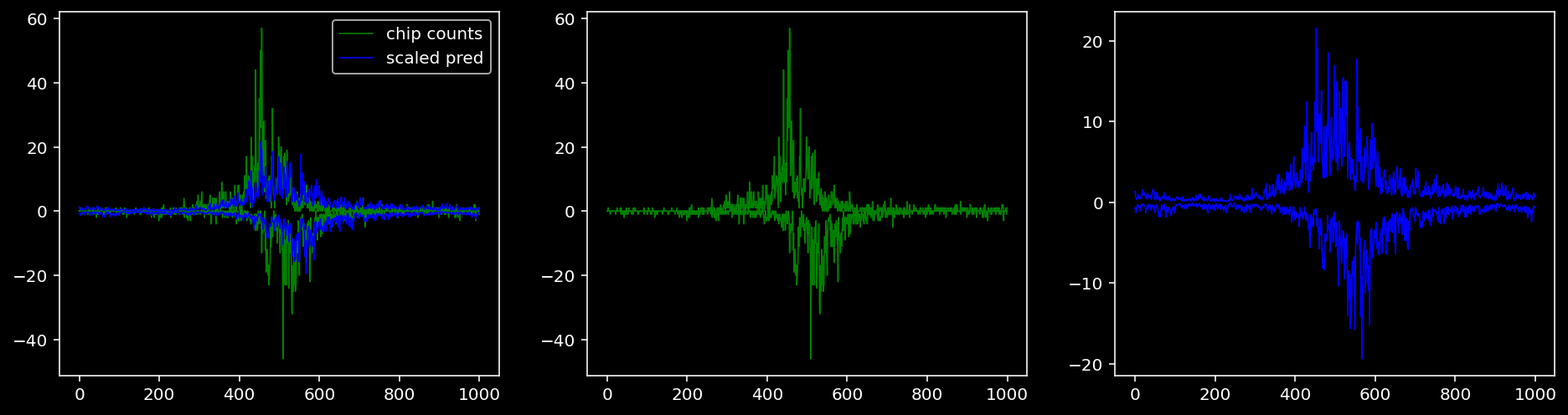
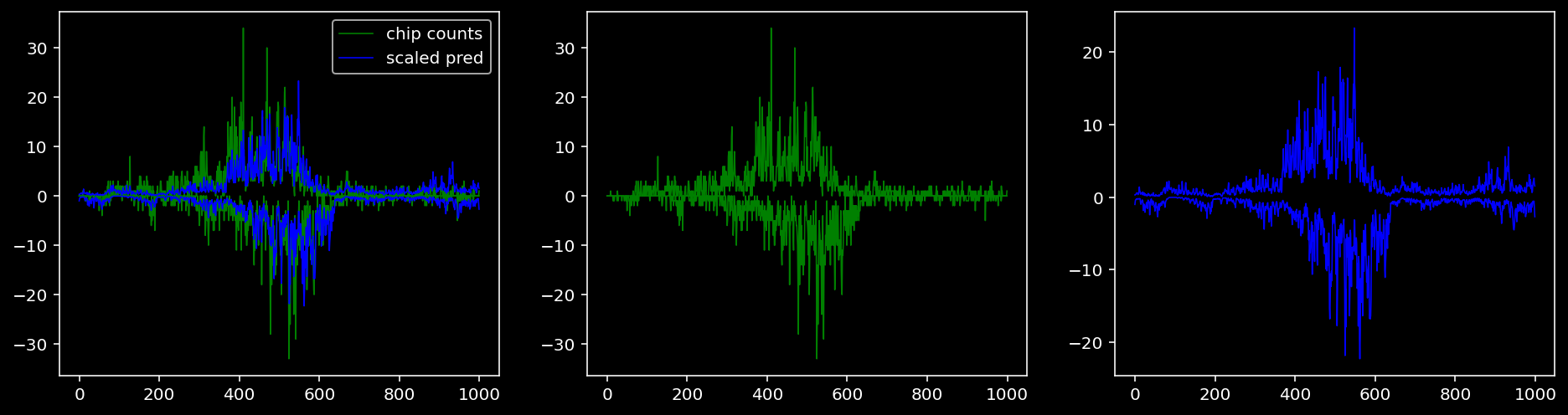
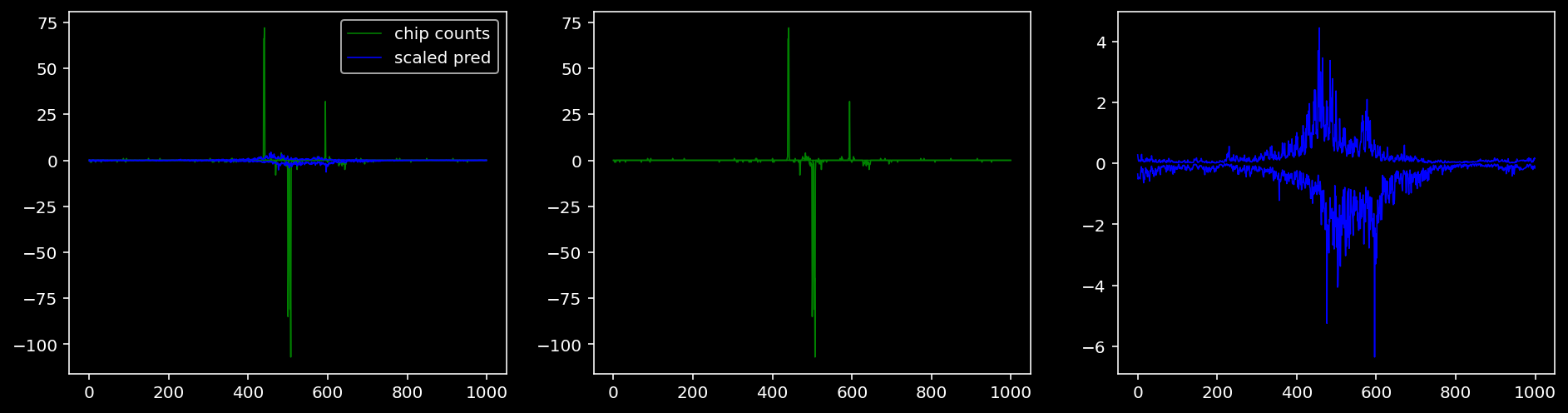
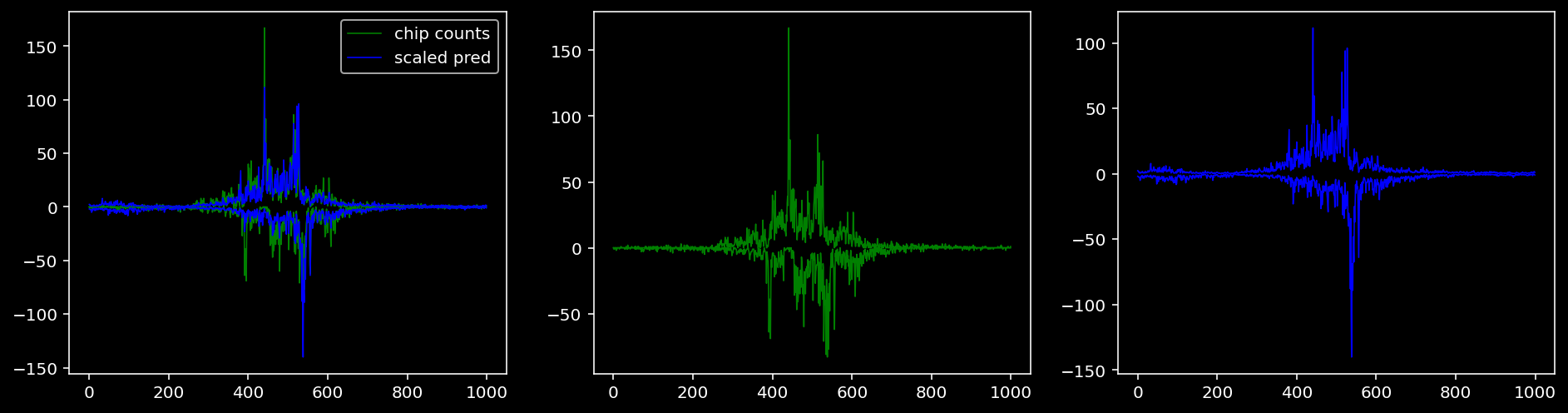
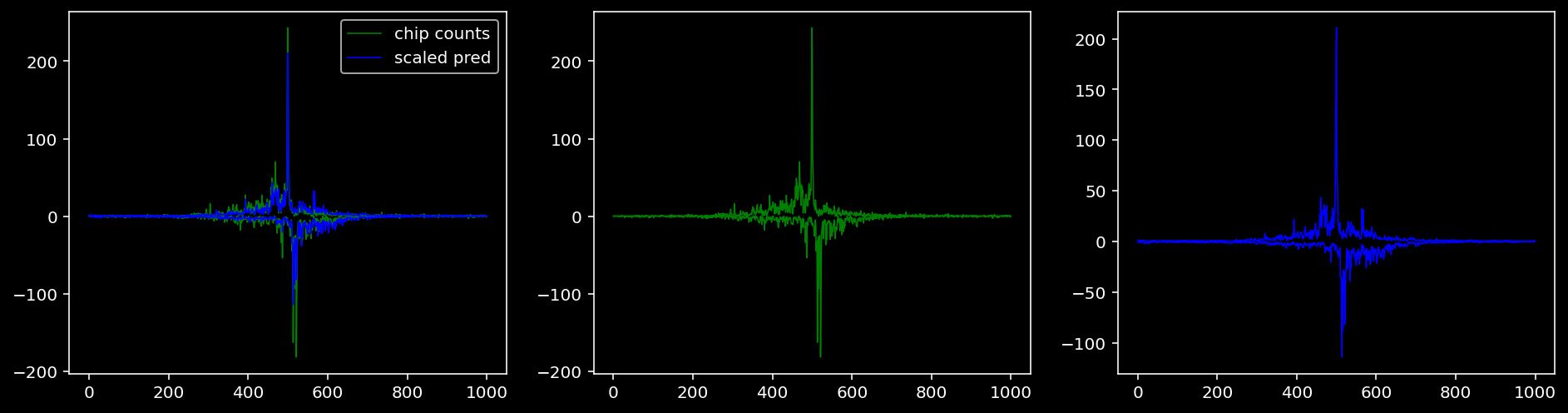
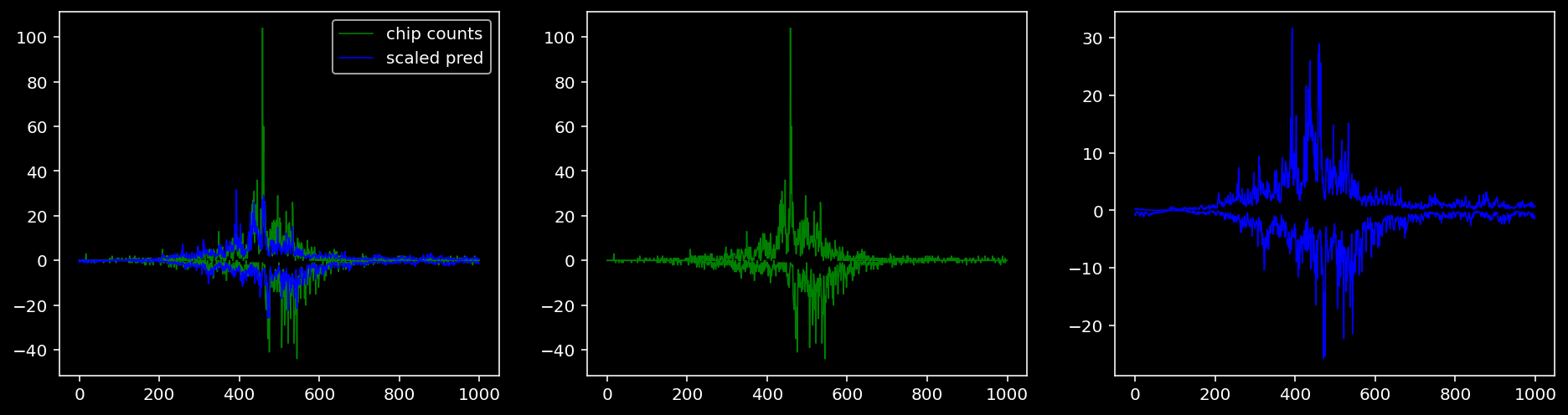
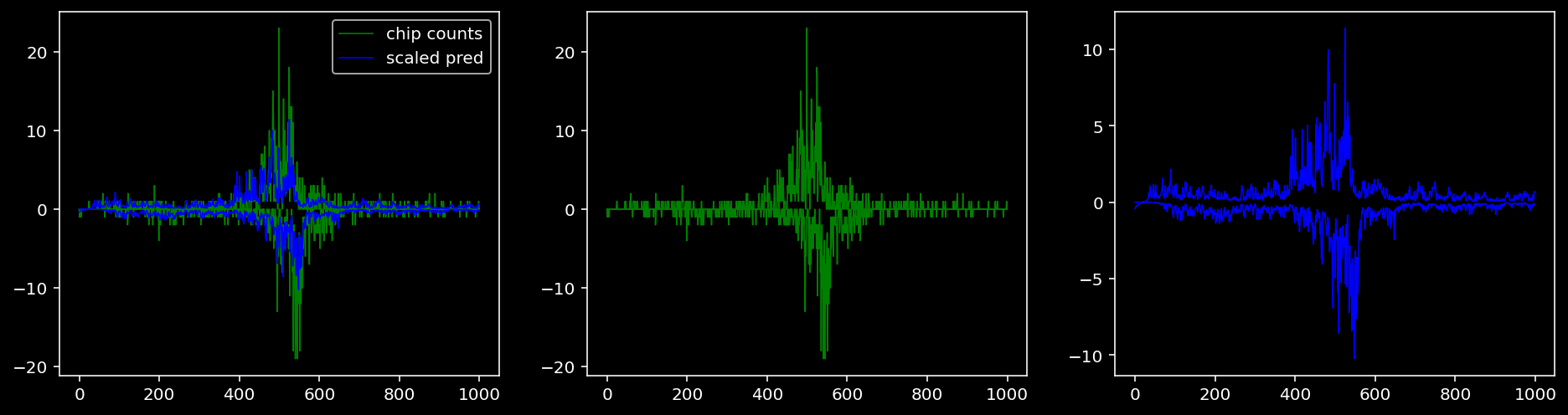
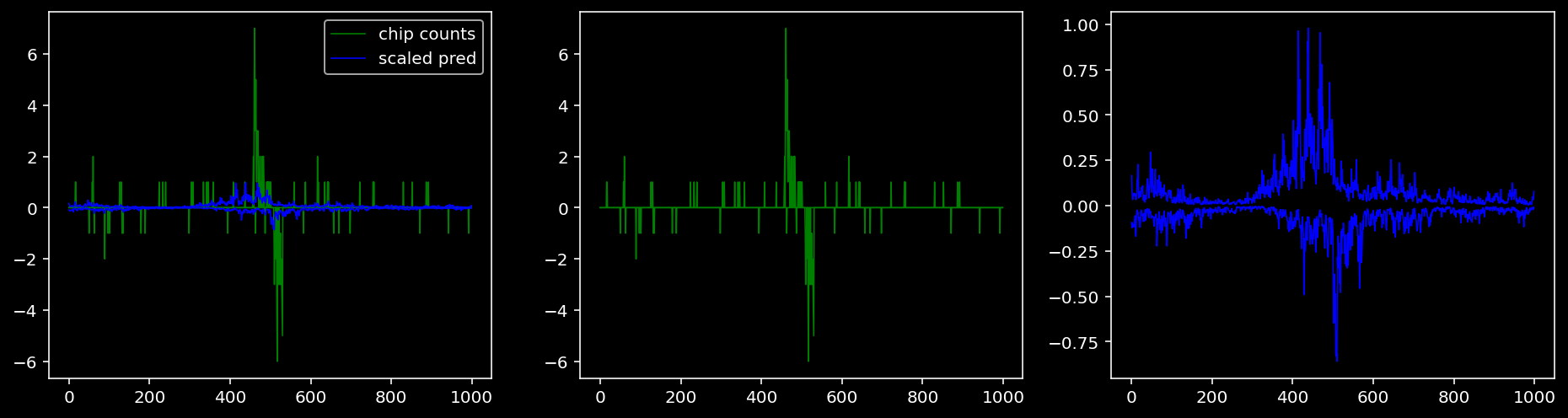
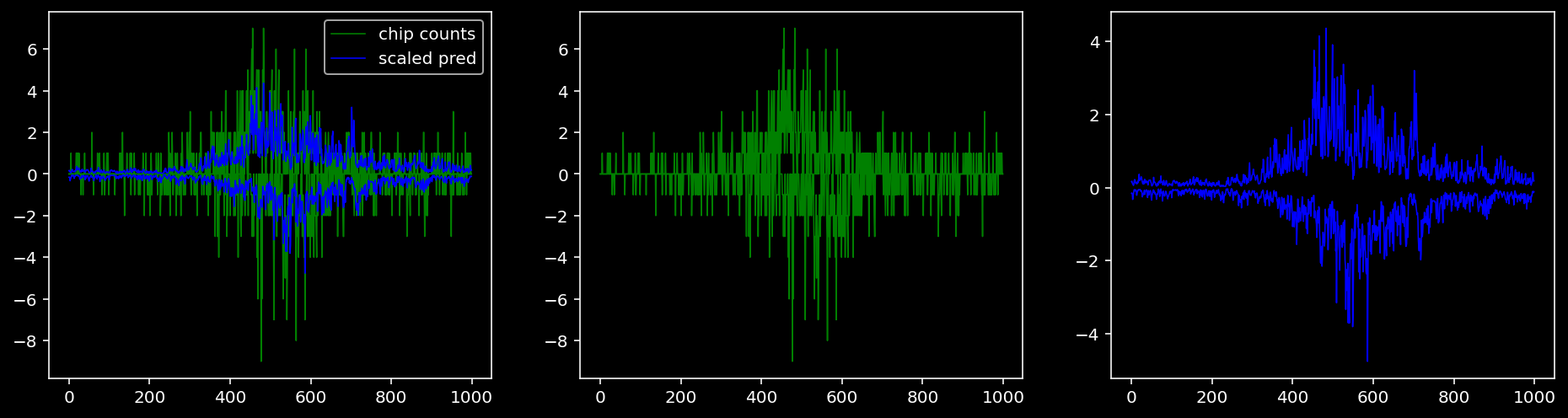
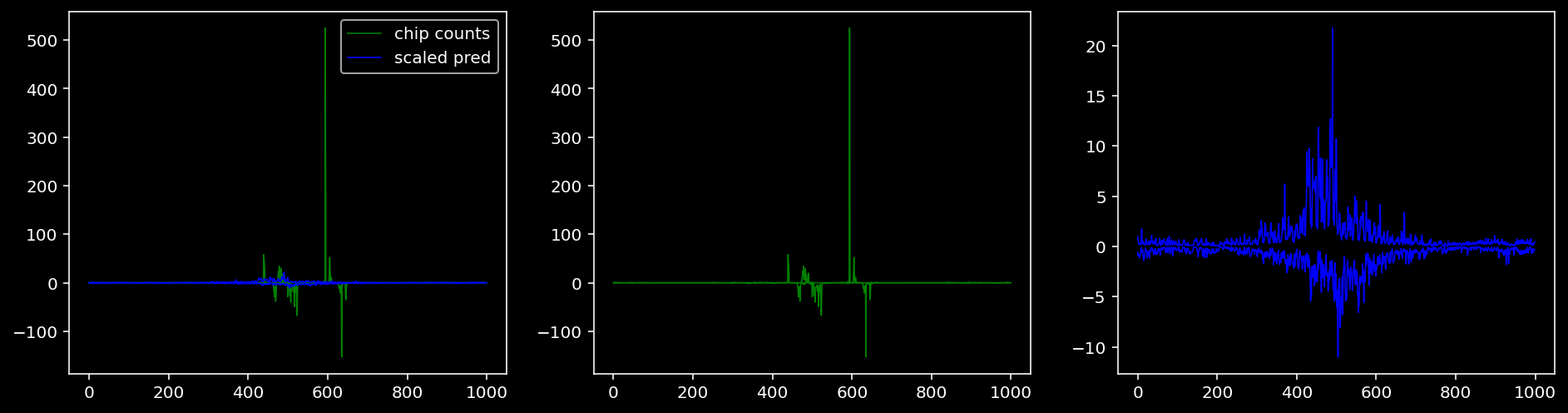
4.4.1.2 Klf4
tf = 1
for i in range(profile_pred.shape[0]):
fig, axis = plt.subplots(1, 3, figsize=(16, 4))
axis[0].plot(tf_counts[i, tf, 0], label="chip counts", color="green", linewidth=lw)
axis[0].plot(-tf_counts[i, tf, 1], color="green", linewidth=lw)
axis[1].plot(tf_counts[i, tf, 0], label="chip counts", color="green", linewidth=lw)
axis[1].plot(-tf_counts[i, tf, 1], color="green", linewidth=lw)
axis[0].plot(scaled_pred[i, tf, 0], label="scaled pred", color="blue", linewidth=lw)
axis[0].plot(-scaled_pred[i, tf, 1], color="blue", linewidth=lw)
axis[2].plot(scaled_pred[i, tf, 0], label="scaled pred", color="blue", linewidth=lw)
axis[2].plot(-scaled_pred[i, tf, 1], color="blue", linewidth=lw)
axis[0].legend()
plt.show()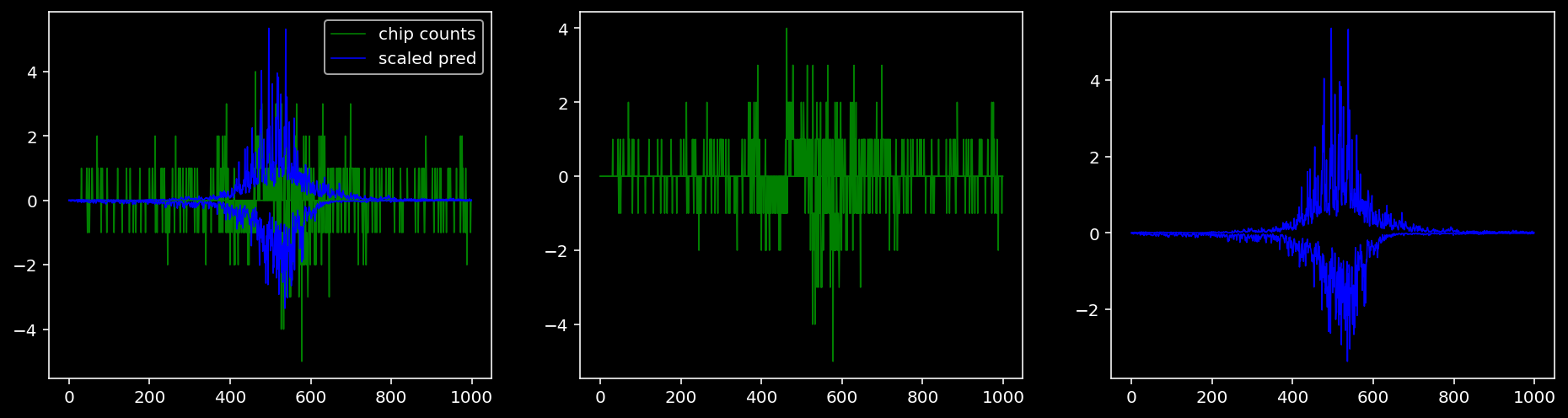
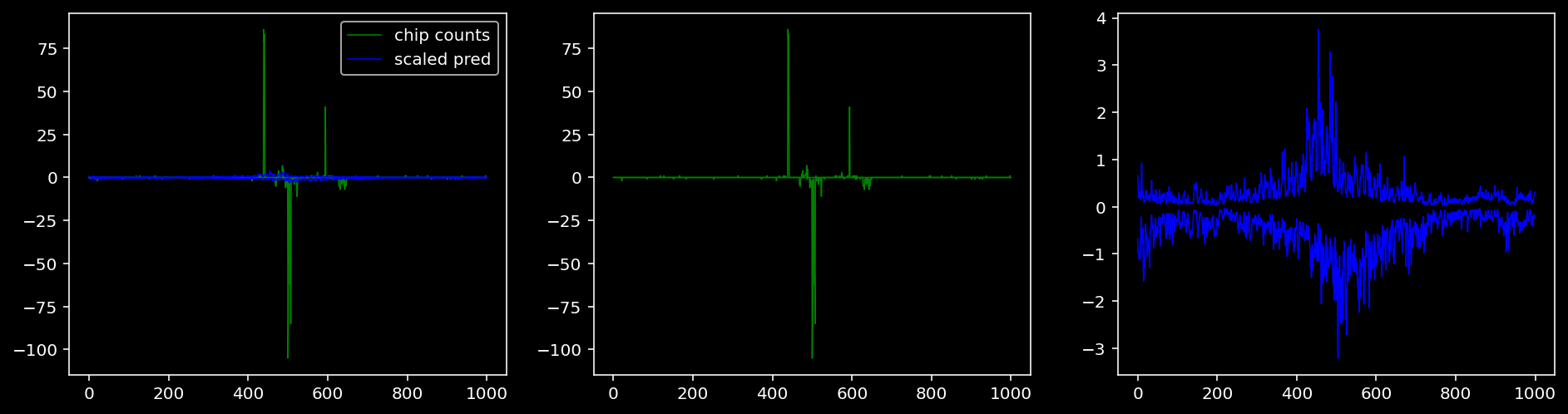
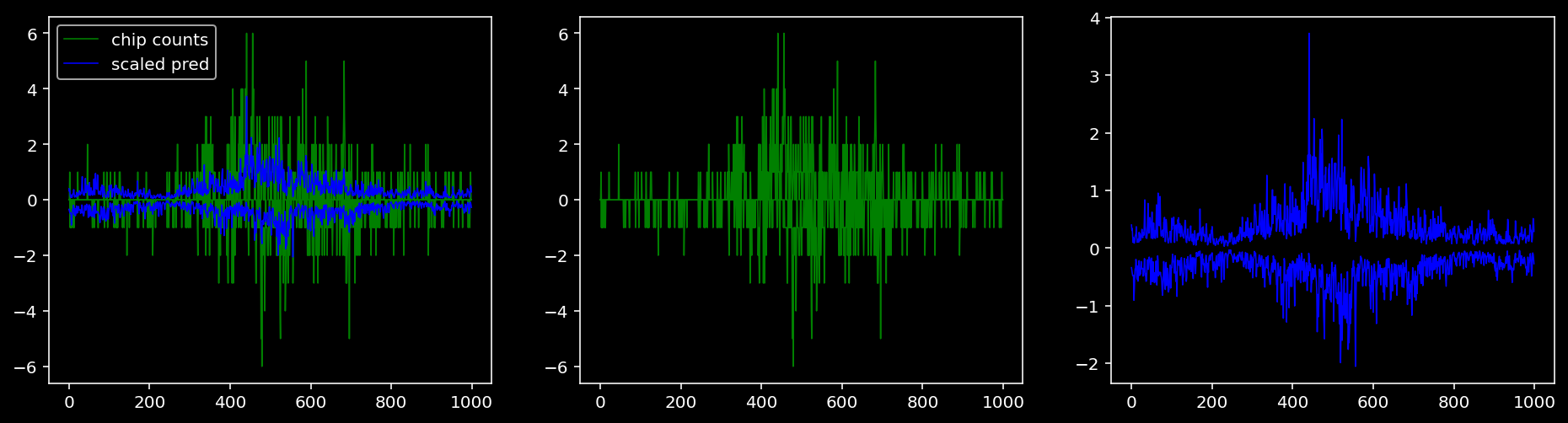
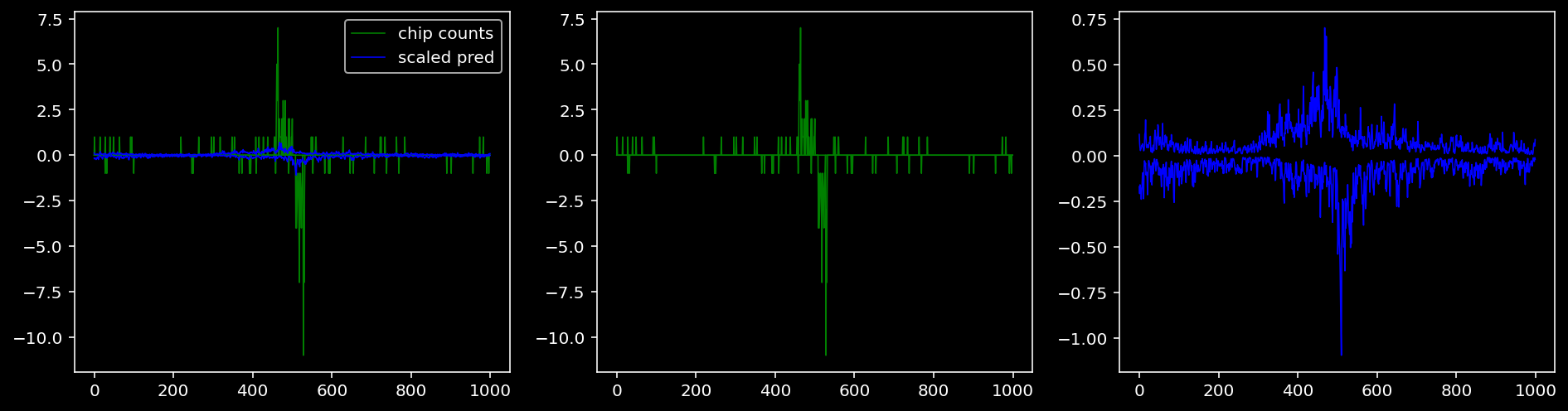
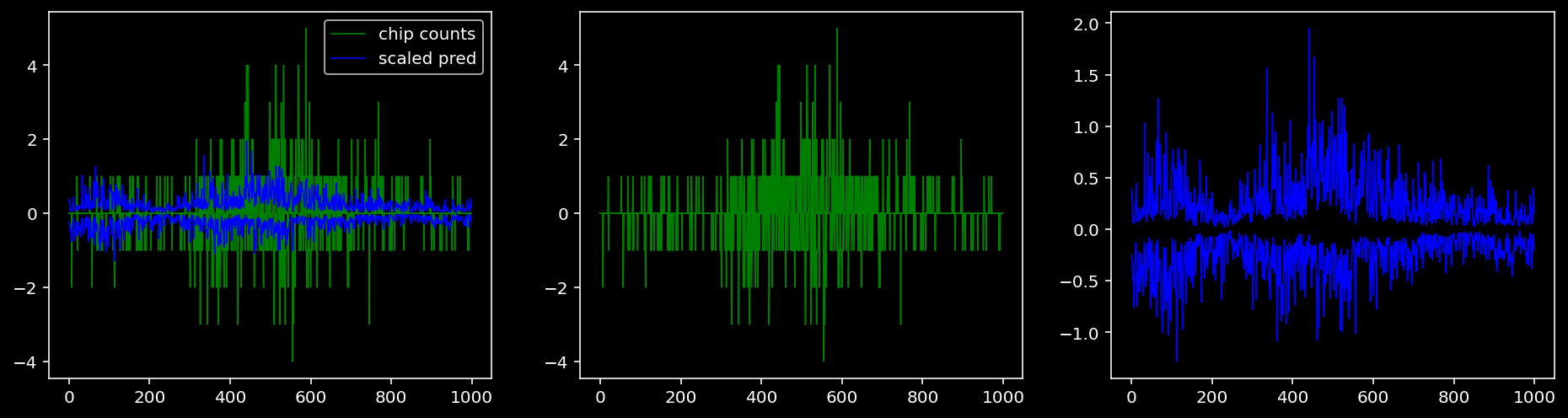
4.4.1.3 Oct4
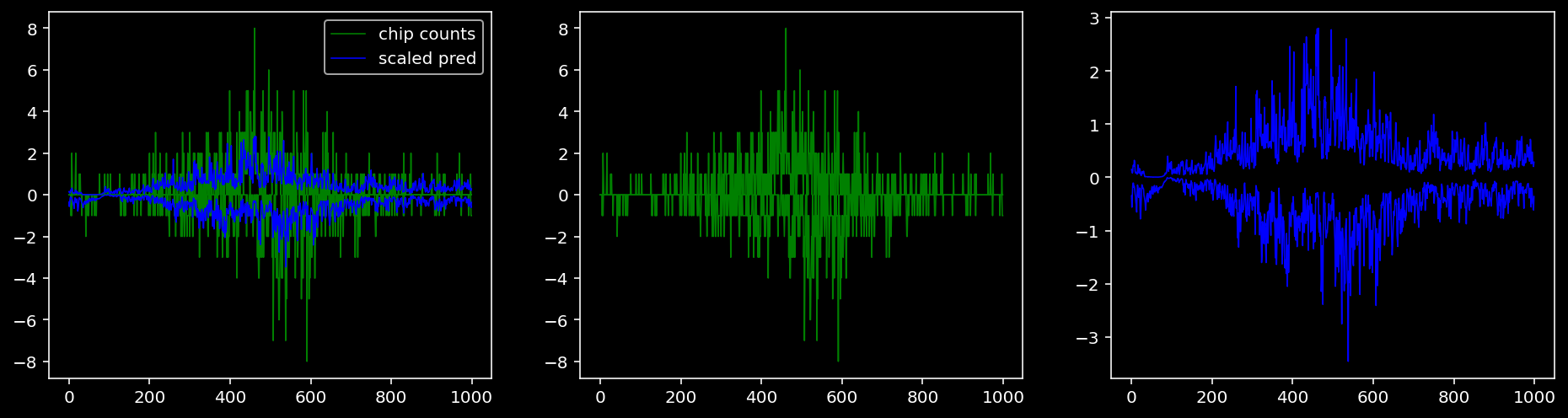
tf = 2
for i in range(profile_pred.shape[0]):
fig, axis = plt.subplots(1, 3, figsize=(16, 4))
axis[0].plot(tf_counts[i, tf, 0], label="chip counts", color="green", linewidth=lw)
axis[0].plot(-tf_counts[i, tf, 1], color="green", linewidth=lw)
axis[1].plot(tf_counts[i, tf, 0], label="chip counts", color="green", linewidth=lw)
axis[1].plot(-tf_counts[i, tf, 1], color="green", linewidth=lw)
axis[0].plot(scaled_pred[i, tf, 0], label="scaled pred", color="blue", linewidth=lw)
axis[0].plot(-scaled_pred[i, tf, 1], color="blue", linewidth=lw)
axis[2].plot(scaled_pred[i, tf, 0], label="scaled pred", color="blue", linewidth=lw)
axis[2].plot(-scaled_pred[i, tf, 1], color="blue", linewidth=lw)
axis[0].legend()
plt.show()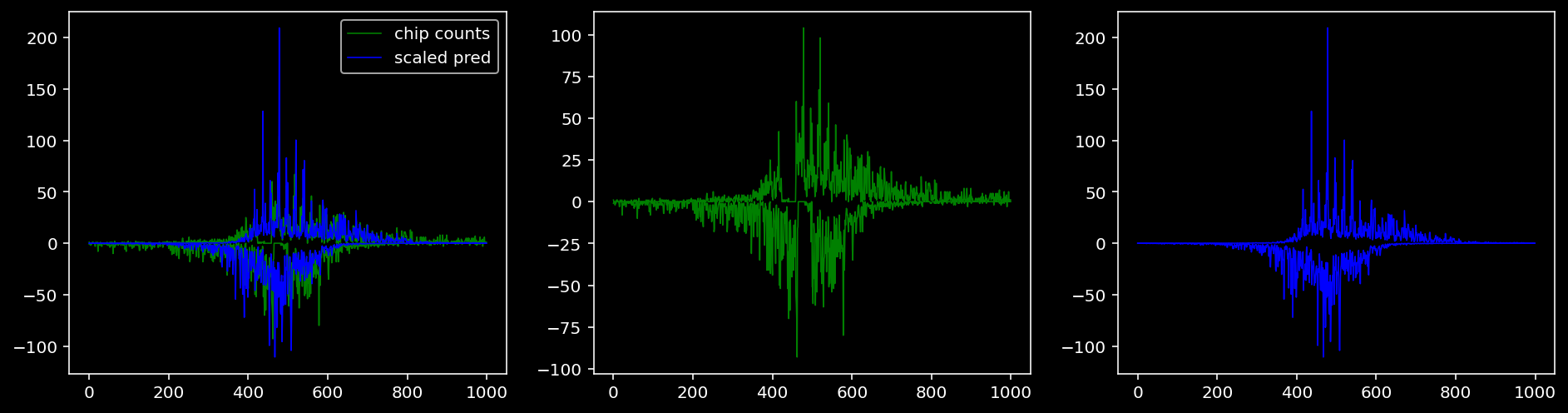
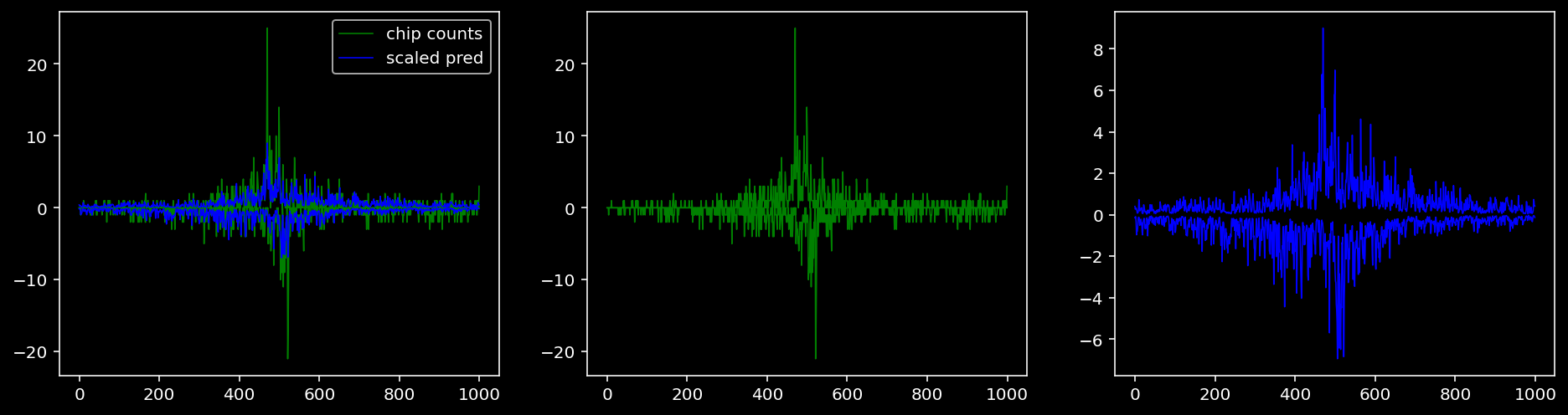
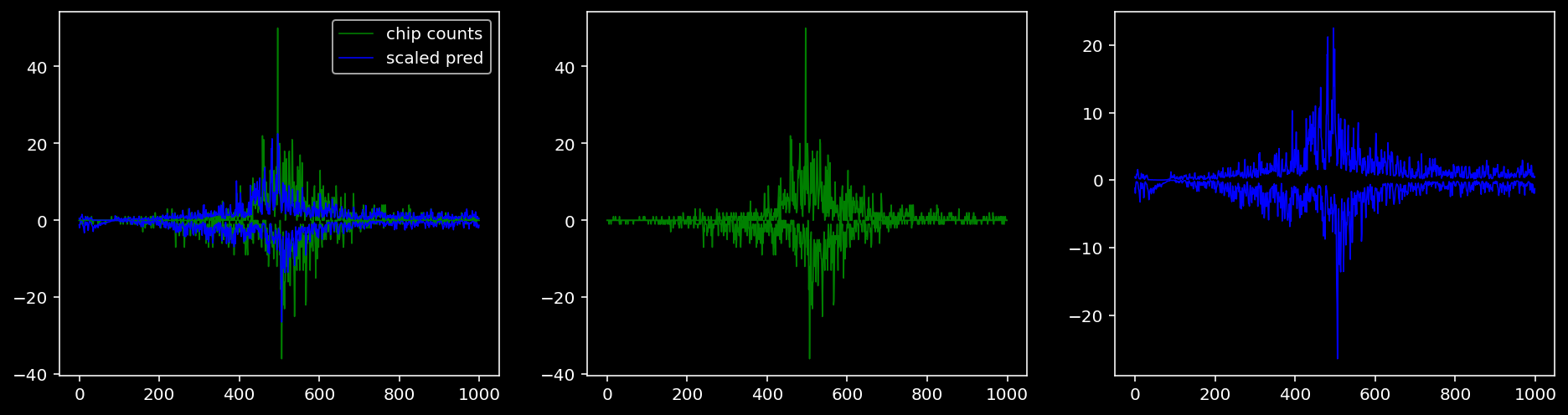
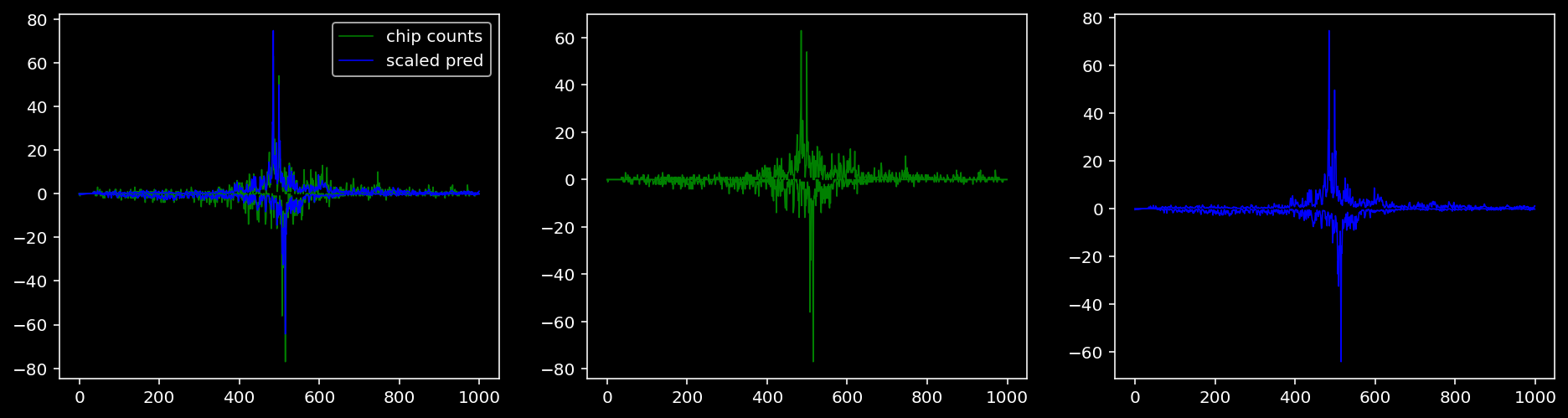
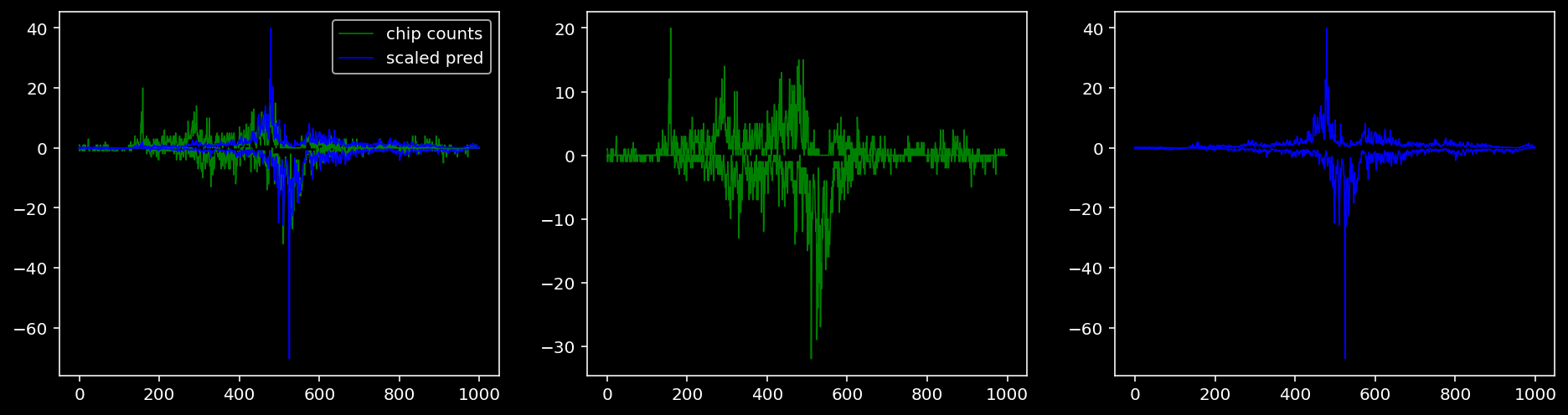
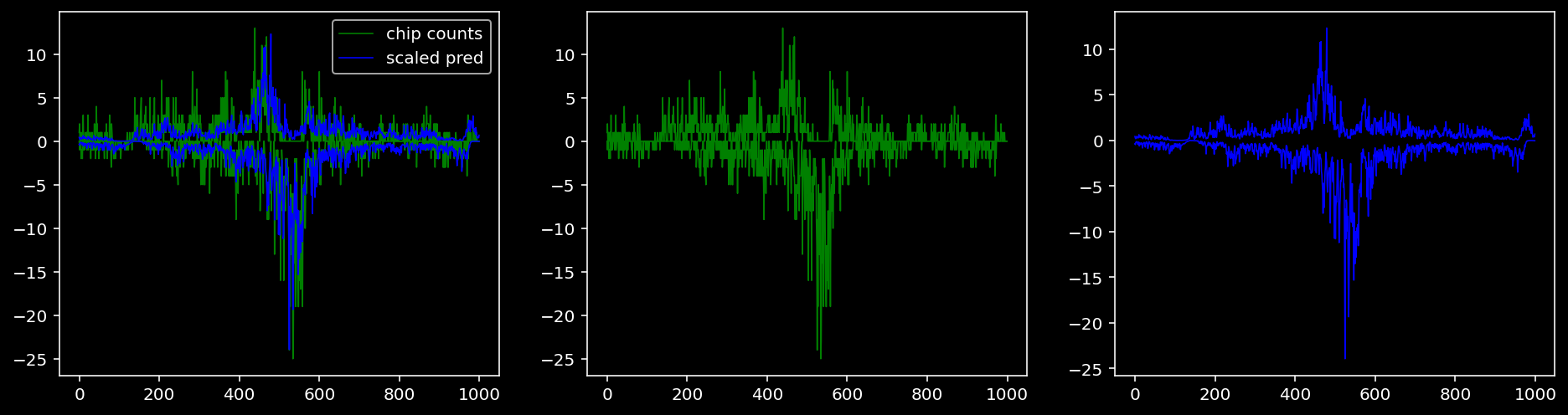
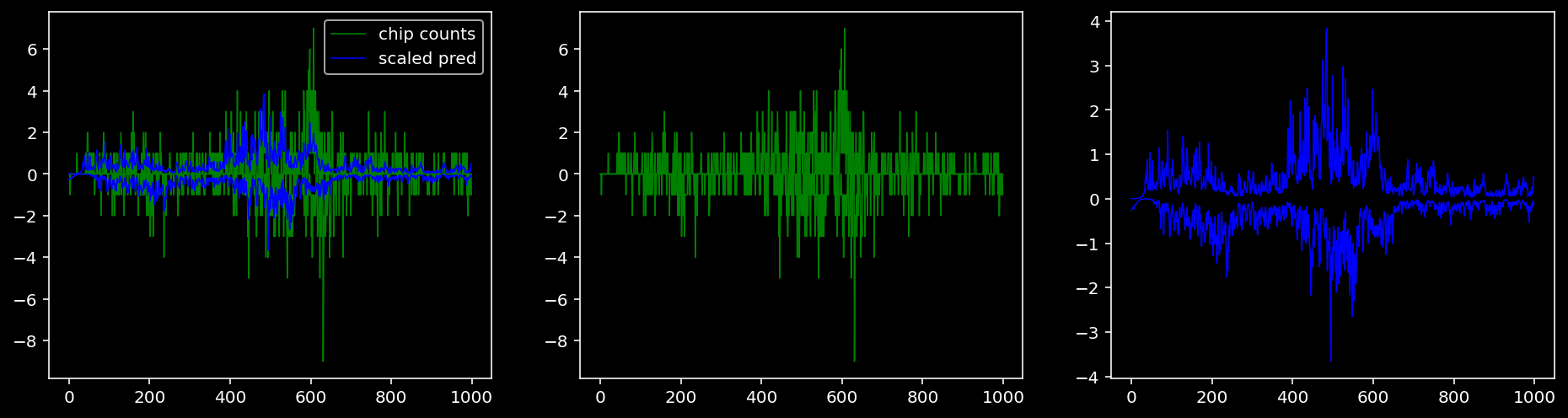
4.4.1.4 Sox2
tf = 3
for i in range(profile_pred.shape[0]):
fig, axis = plt.subplots(1, 3, figsize=(16, 4))
axis[0].plot(tf_counts[i, tf, 0], label="chip counts", color="green", linewidth=lw)
axis[0].plot(-tf_counts[i, tf, 1], color="green", linewidth=lw)
axis[1].plot(tf_counts[i, tf, 0], label="chip counts", color="green", linewidth=lw)
axis[1].plot(-tf_counts[i, tf, 1], color="green", linewidth=lw)
axis[0].plot(scaled_pred[i, tf, 0], label="scaled pred", color="blue", linewidth=lw)
axis[0].plot(-scaled_pred[i, tf, 1], color="blue", linewidth=lw)
axis[2].plot(scaled_pred[i, tf, 0], label="scaled pred", color="blue", linewidth=lw)
axis[2].plot(-scaled_pred[i, tf, 1], color="blue", linewidth=lw)
axis[0].legend()
plt.show()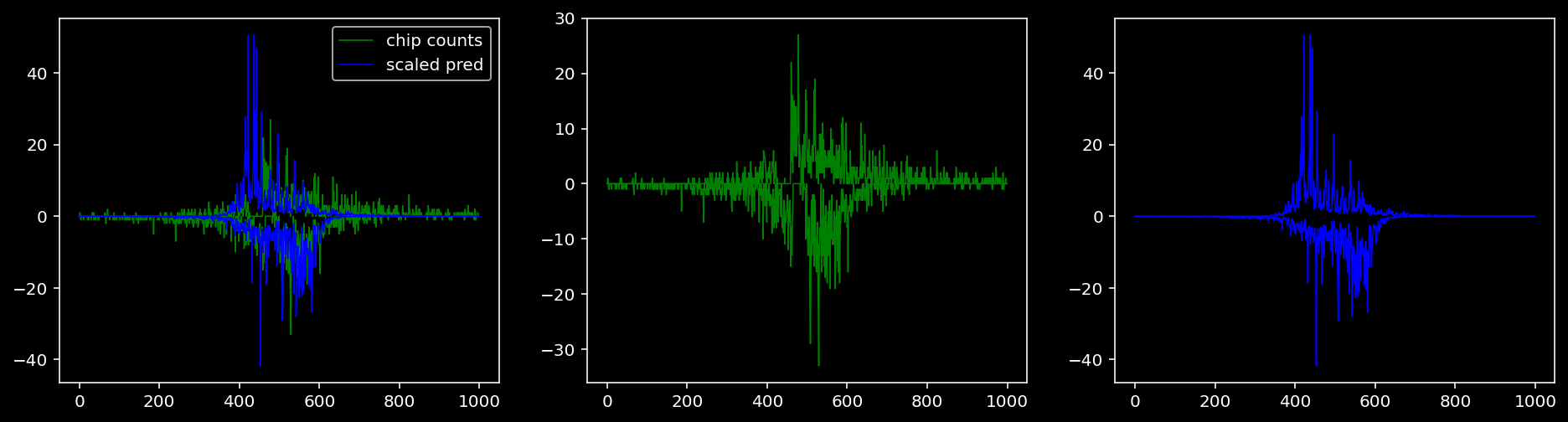
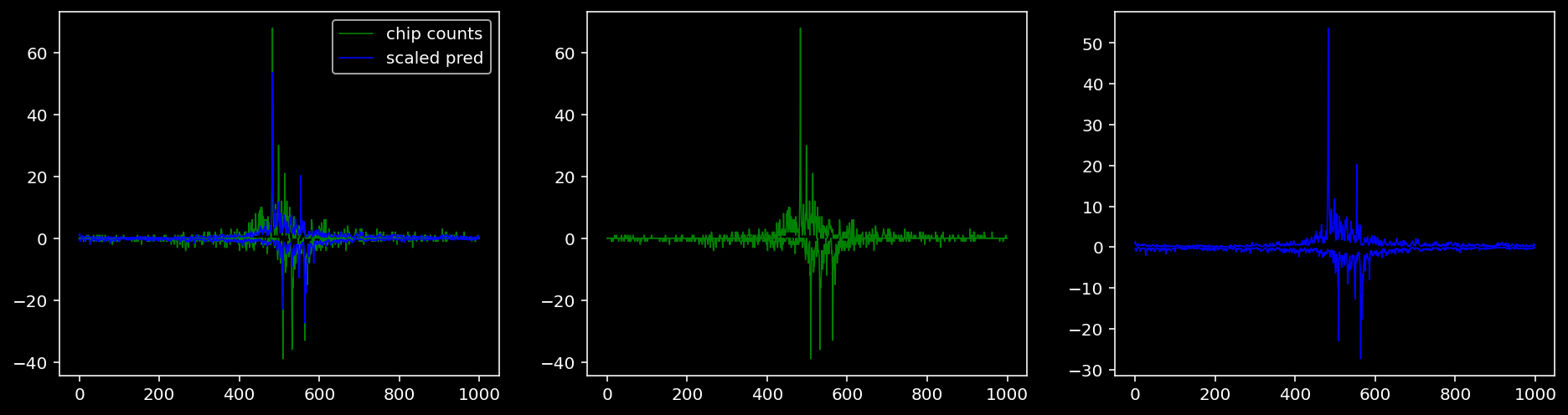
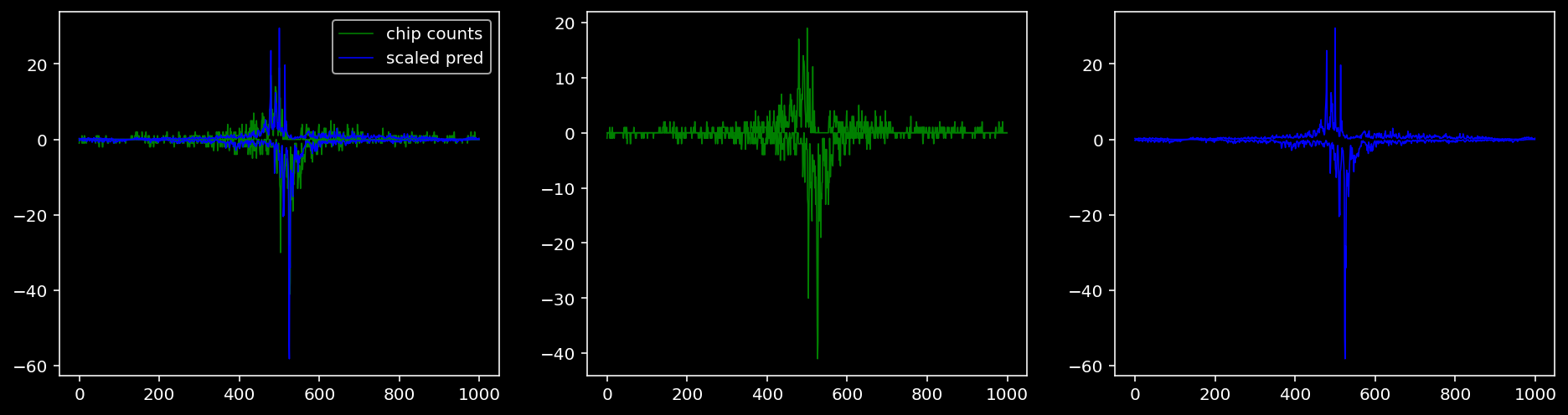
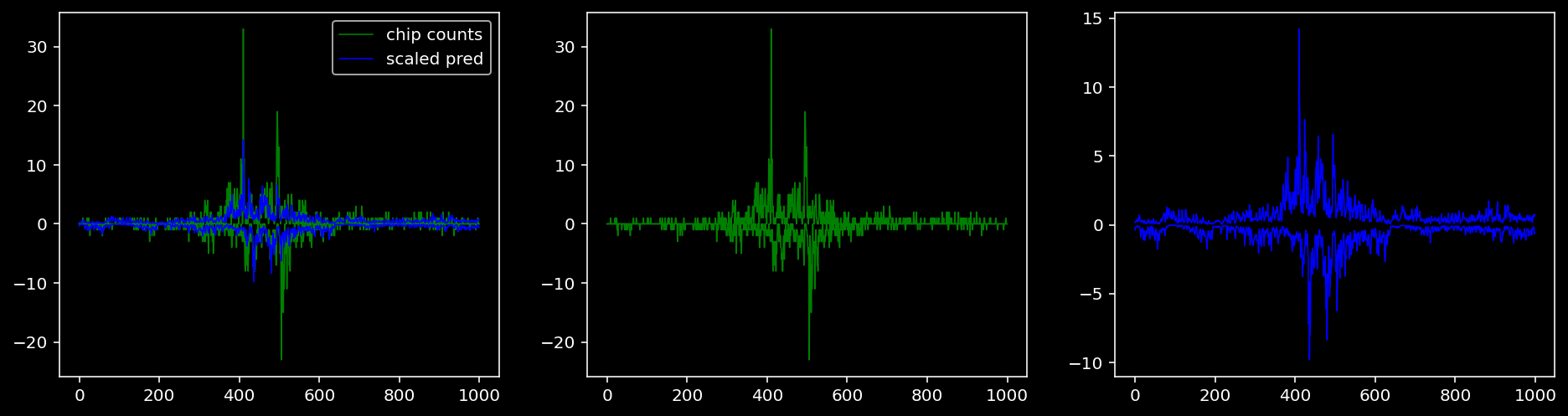
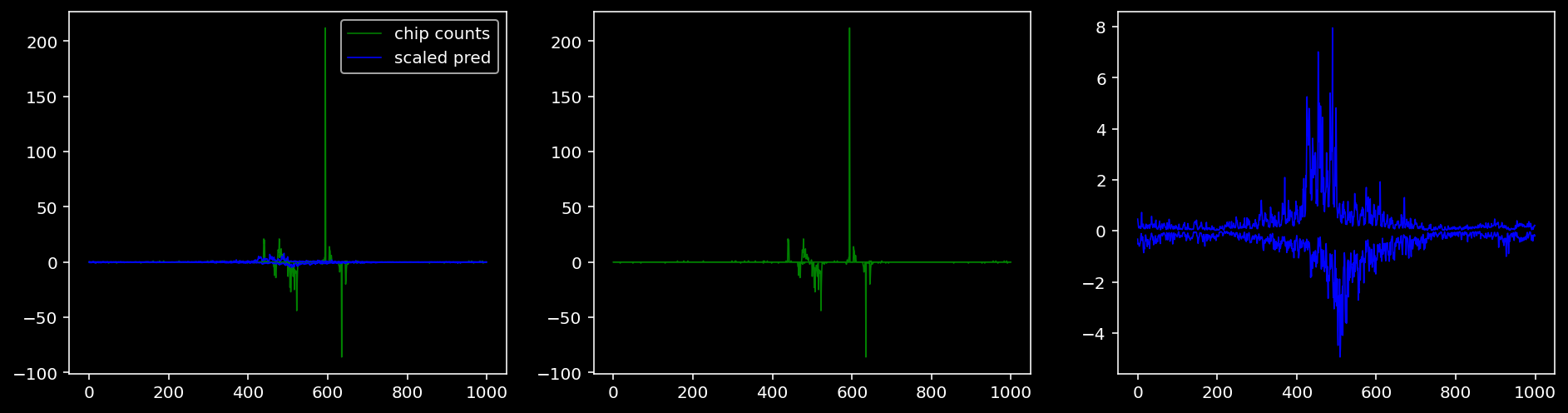
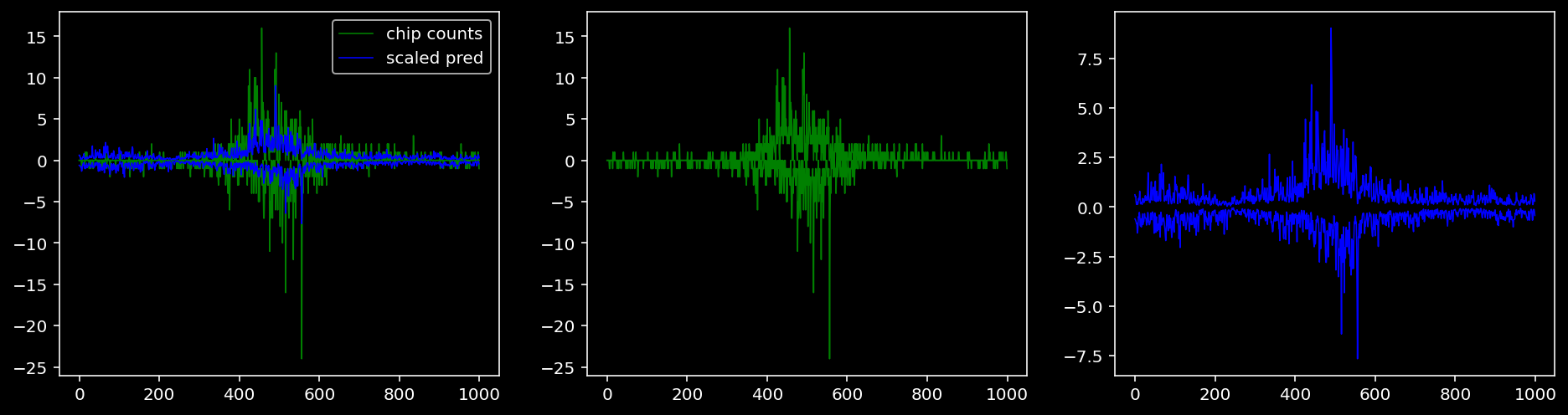
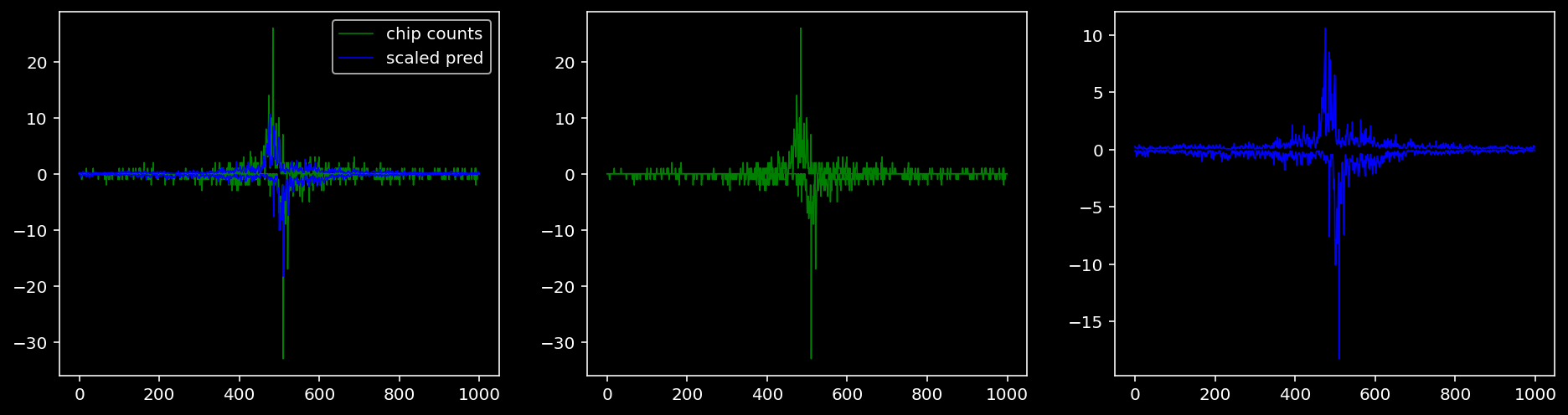
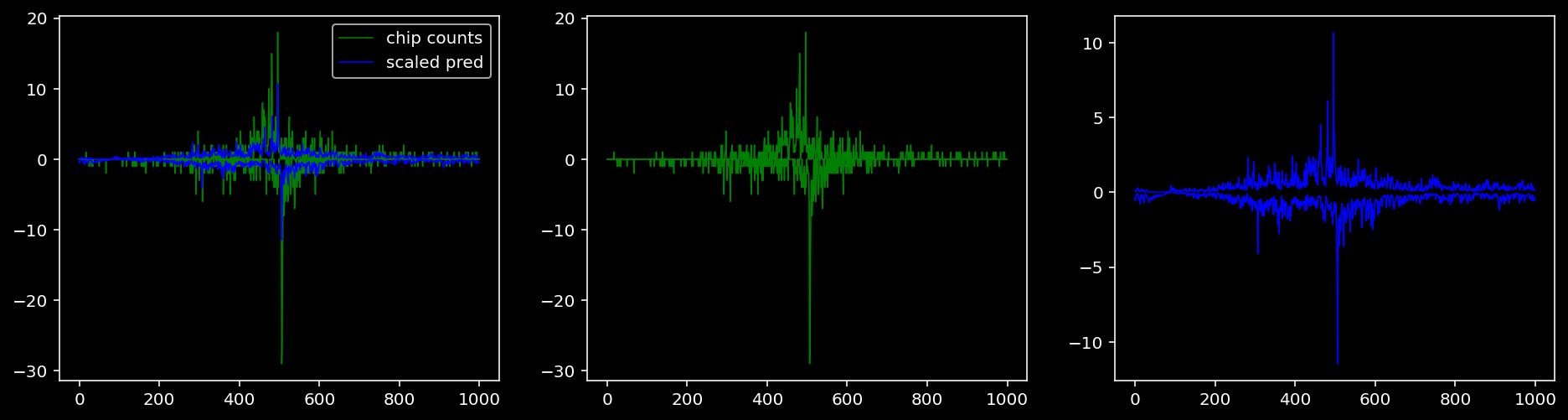
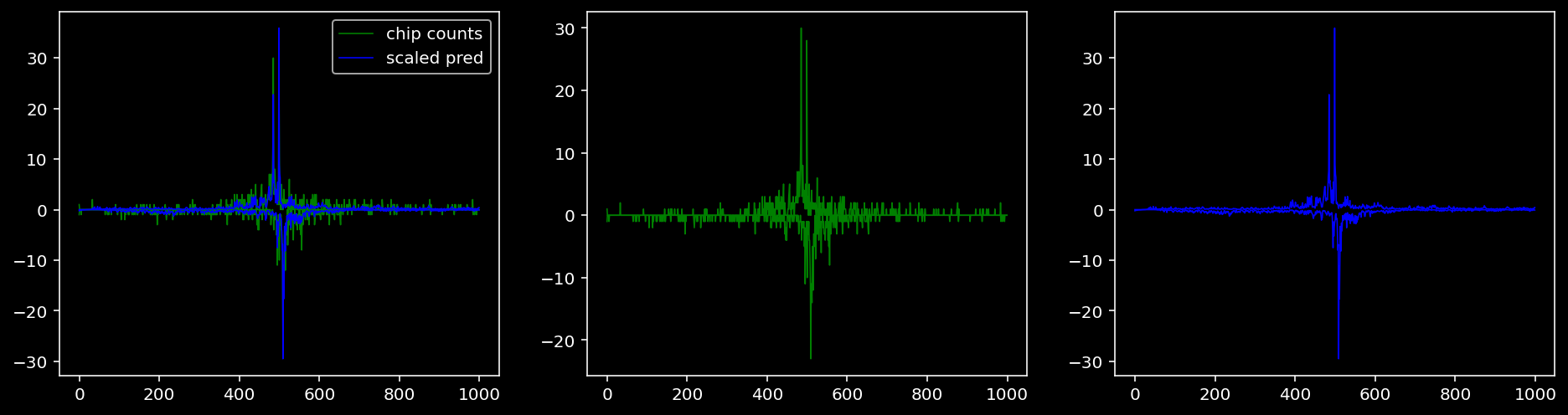
4.4.2 Precision and Recall
test_pred = torch.zeros(test_dataset.tf_counts.shape, dtype=torch.float32).to(device)
with torch.no_grad():
for batch_idx, data in enumerate(test_dataloader):
#print(batch_idx, batch_idx + 100)#, data)
one_hot, tf_counts, ctrl_counts, ctrl_smooth = data
one_hot, tf_counts, ctrl_counts, ctrl_smooth = one_hot.to(device), tf_counts.to(device), ctrl_counts.to(device), ctrl_smooth.to(device)
profile_pred = model.forward(sequence=one_hot, bias_raw=ctrl_counts, bias_smooth=ctrl_smooth)
#print(profile_pred.shape)
start = batch_idx*BATCH_SIZE
end = (batch_idx+1)*BATCH_SIZE if (batch_idx+1)*BATCH_SIZE < test_dataset.tf_counts.shape[0] else test_dataset.tf_counts.shape[0]
test_pred[start:end, :, :, :] = profile_preddef plot_prc(test_dataset, test_pred, tf_index, tf_name, plot = True):
true_counts = test_dataset.tf_counts.copy()
#subset for one tf
tf_counts = true_counts[:, tf_index, :, :]
test_pred = test_pred.cpu().numpy().copy()
assert np.allclose(test_pred.sum(axis=-1), 1)
# subset for one tf
tf_pred = test_pred[:, tf_index, :, :]
binary_labels, pred_subset, random = binary_labels_from_counts(tf_counts, tf_pred, verbose=False)
precision, recall, thresholds = skm.precision_recall_curve(binary_labels, pred_subset)
if plot:
plt.plot(precision, recall, label=f"{tf}")
plt.title(f"Precision-Recall Curve: {tf_name}")
plt.xlabel("recall")
plt.ylabel("precision")
else:
return precision, recall, thresholdsfor i, tf in enumerate(TF_LIST):
plot_prc(test_dataset, test_pred, i, tf, plot=True)
plt.legend()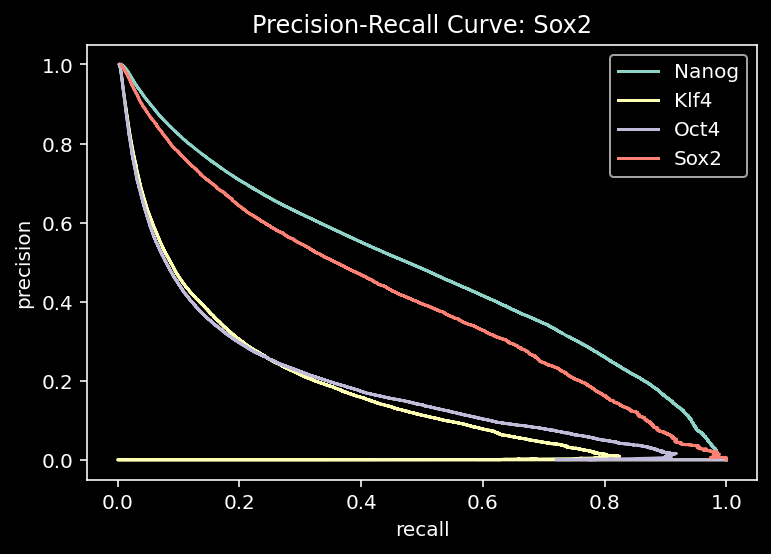
df = pd.DataFrame(columns=["TF", "precision", "recall"])
for i, tf in enumerate(TF_LIST):
precision, recall, thresholds = plot_prc(test_dataset, test_pred, i, tf, plot=False)
tmp_df = pd.DataFrame({
"TF": tf,
"precision": precision,
"recall": recall,
})
df = df.append(tmp_df)
df.to_csv("/home/philipp/BPNet/out/pr_curve_all_tfs_shape_model.csv", index=False)
del df, tmp_df/tmp/ipykernel_1221851/1134583418.py:9: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)/tmp/ipykernel_1221851/1134583418.py:9: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)/tmp/ipykernel_1221851/1134583418.py:9: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)/tmp/ipykernel_1221851/1134583418.py:9: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)# loop over all four TFs:
true_counts = test_dataset.tf_counts.copy()
all_pred = test_pred.cpu().numpy().copy()
patchcap = test_dataset.ctrl_counts.copy()
assert np.allclose(all_pred.sum(axis=-1), 1)
for tf_index, tf in enumerate(TF_LIST):
patchcap_cp = patchcap.copy()
# subset for one tf
pred = all_pred[:, tf_index, :, :]
counts = true_counts[:, tf_index, :, :]
# compute auPRC fro all bins
all = compute_auprc_bins(counts, pred, patchcap_cp, verbose=False)
df = pd.DataFrame(all)
df.to_csv(f"/home/philipp/BPNet/out/binsizes_auprc_{tf}_shape_model.csv")
sns.scatterplot(x=df["binsize"], y=df["auprc"], label="BPNet")
sns.scatterplot(x=df["binsize"], y=df["random_auprc"], label="random profile")
sns.scatterplot(x=df["binsize"], y=df["average_auprc"], label="average profile")
sns.scatterplot(x=df["binsize"], y=df["patchcap_auprc"], label="PATCH-CAP")
plt.title(f"{tf}")
plt.legend()
plt.show()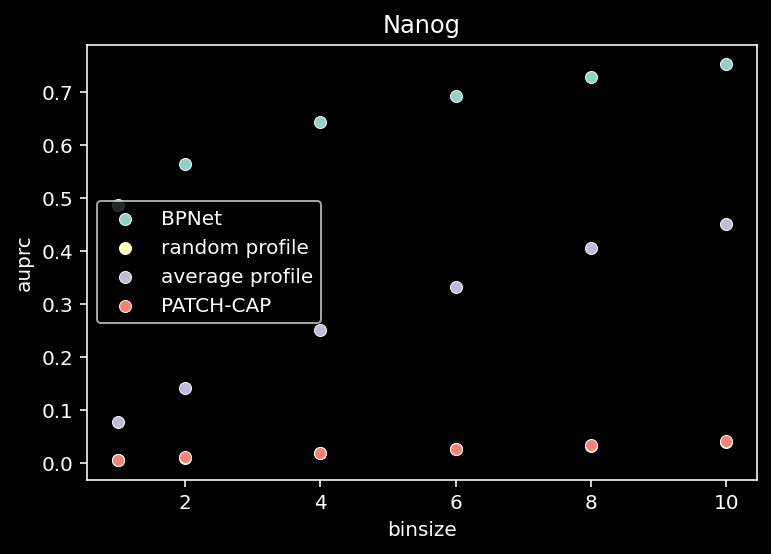
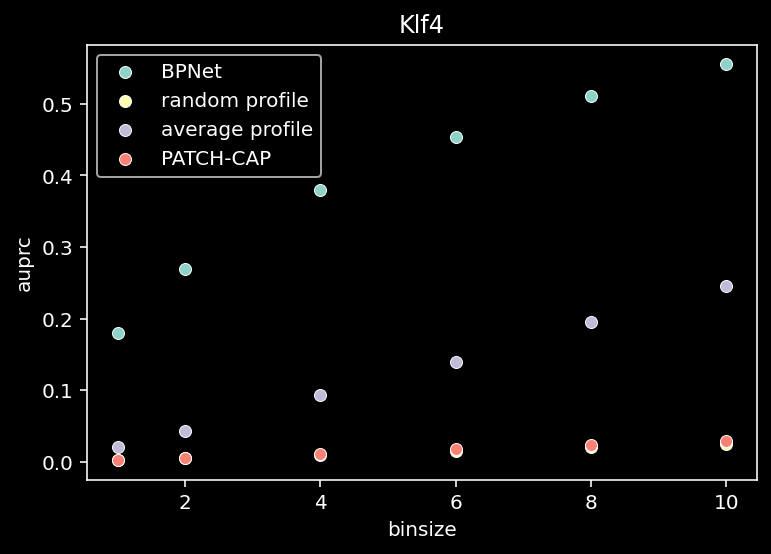
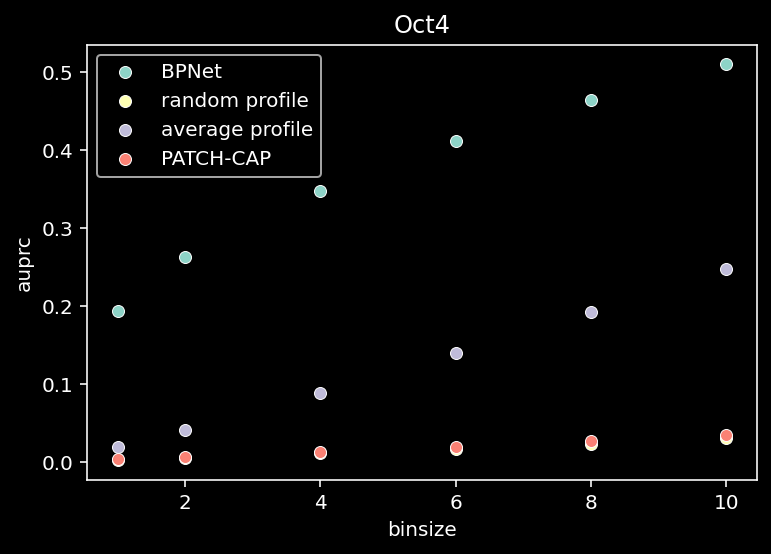
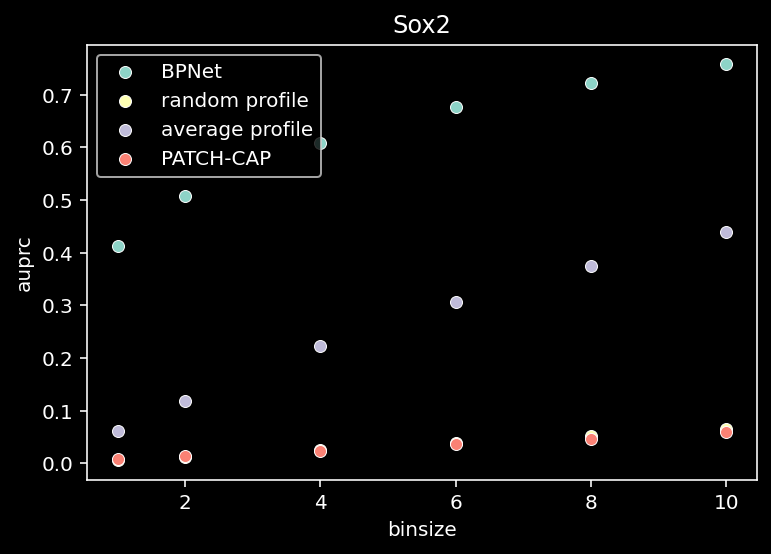
5 Shape & Total Counts Prediction
5.1 Train Loop
model = BPNet(n_dil_layers=9, TF_list=TF_LIST, pred_total=True, bias_track=True).to(device)
optimizer = optim.Adam(model.parameters(), lr=4*1e-4)
train_loader=DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=0, pin_memory=True)
tune_loader=DataLoader(tune_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=0, pin_memory=True)
train_shape_loss, train_count_loss, train_loss = [], [], []
test_shape_loss, test_count_loss, test_loss = [], [], []
patience_counter = 0
for epoch in range(MAX_EPOCHS):
# test
test_shape_loss_epoch, test_count_loss_epoch, test_loss_epoch = [], [], []
with torch.no_grad():
for one_hot, tf_counts, ctrl_counts, ctrl_smooth in tune_loader:
one_hot, tf_counts, ctrl_counts, ctrl_smooth = one_hot.to(device), tf_counts.to(device), ctrl_counts.to(device), ctrl_smooth.to(device)
shape_pred, count_pred = model.forward(sequence=one_hot, bias_raw=ctrl_counts, bias_smooth=ctrl_smooth)
shape_loss = neg_log_multinomial(k_obs=tf_counts, p_pred=shape_pred, device=device)
if count_pred.min() < 0:
break
count_loss = ((torch.log(1 + count_pred) - torch.log(1 + tf_counts.sum(axis=-1)))**2).mean()
loss = shape_loss + lambda_param * count_loss
test_shape_loss_epoch.append(shape_loss.item())
test_count_loss_epoch.append(count_loss.item())
test_loss_epoch.append(loss.item())
test_shape_loss.append(sum(test_shape_loss_epoch)/len(test_shape_loss_epoch))
test_count_loss.append(sum(test_count_loss_epoch)/len(test_count_loss_epoch))
test_loss.append(sum(test_loss_epoch)/len(test_loss_epoch))
# train
model.train()
train_shape_loss_epoch, train_count_loss_epoch, train_loss_epoch = [], [], []
for one_hot, tf_counts, ctrl_counts, ctrl_smooth in train_loader:
one_hot, tf_counts, ctrl_counts, ctrl_smooth = one_hot.to(device), tf_counts.to(device), ctrl_counts.to(device), ctrl_smooth.to(device)
optimizer.zero_grad()
shape_pred, count_pred = model.forward(sequence=one_hot, bias_raw=ctrl_counts, bias_smooth=ctrl_smooth)
shape_loss = neg_log_multinomial(k_obs=tf_counts, p_pred=shape_pred, device=device)
count_loss = ((torch.log(1 + count_pred) - torch.log(1 + tf_counts.sum(axis=-1)))**2).mean()
loss = shape_loss + lambda_param * count_loss
train_shape_loss_epoch.append(shape_loss.item())
train_count_loss_epoch.append(count_loss.item())
train_loss_epoch.append(loss.item())
loss.backward()
optimizer.step()
train_shape_loss.append(sum(train_shape_loss_epoch)/len(train_shape_loss_epoch))
train_count_loss.append(sum(train_count_loss_epoch)/len(train_count_loss_epoch))
train_loss.append(sum(train_loss_epoch)/len(train_loss_epoch))
if test_loss[-1] > np.array(test_loss).min():
patience_counter += 1
else:
patience_counter = 0
best_state_dict = model.state_dict()
if patience_counter == EARLY_STOP_PATIENCE:
break
if RESTORE_BEST_WEIGHTS:
model.load_state_dict(best_state_dict)5.2 Train and Tune Loss
df = pd.DataFrame({"epoch": np.arange(1, epoch+2), "train_shape": train_shape_loss, "test_shape": test_shape_loss, "train_count": train_count_loss, "test_count": test_count_loss, "train": train_loss, "test": test_loss})
df.to_csv("/home/philipp/BPNet/out/shape_counts_loss.csv")
fig, axis = plt.subplots(1, 3, figsize=(12, 3))
axis[0].plot(np.arange(1, epoch+2), np.array(train_shape_loss), label="train")
axis[0].plot(np.arange(1, epoch+2), np.array(test_shape_loss), label="test")
axis[0].set_xlabel("Epoch")
axis[0].set_ylabel("Loss")
axis[0].set_title("Shape Loss")
axis[1].plot(np.arange(1, epoch+2), np.array(train_count_loss), label="train")
axis[1].plot(np.arange(1, epoch+2), np.array(test_count_loss), label="test")
axis[1].set_xlabel("Epoch")
axis[1].set_ylabel("Loss")
axis[1].set_title("Count Loss")
axis[2].plot(np.arange(1, epoch+2), np.array(train_loss), label="train")
axis[2].plot(np.arange(1, epoch+2), np.array(test_loss), label="test")
axis[2].set_xlabel("Epoch")
axis[2].set_ylabel("Loss")
axis[2].set_title("Combined Loss")
plt.legend()
plt.show()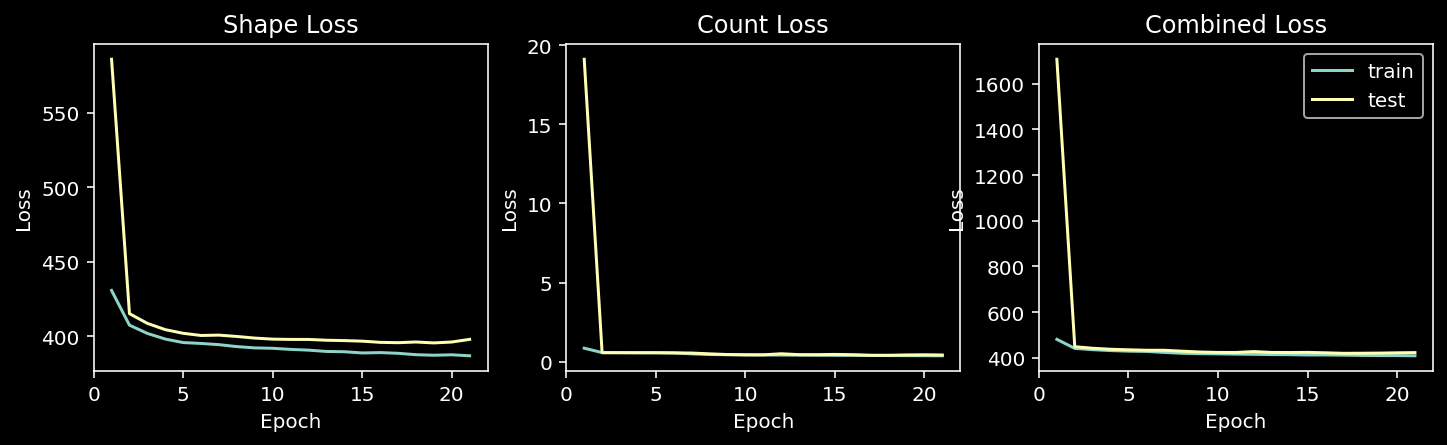
5.3 Save Model
torch.save(obj=model, f="/home/philipp/BPNet/trained_models/all_tfs_model.pt")5.4 Evaluation
model = torch.load("/home/philipp/BPNet/trained_models/all_tfs_model.pt")5.4.1 Check Examples
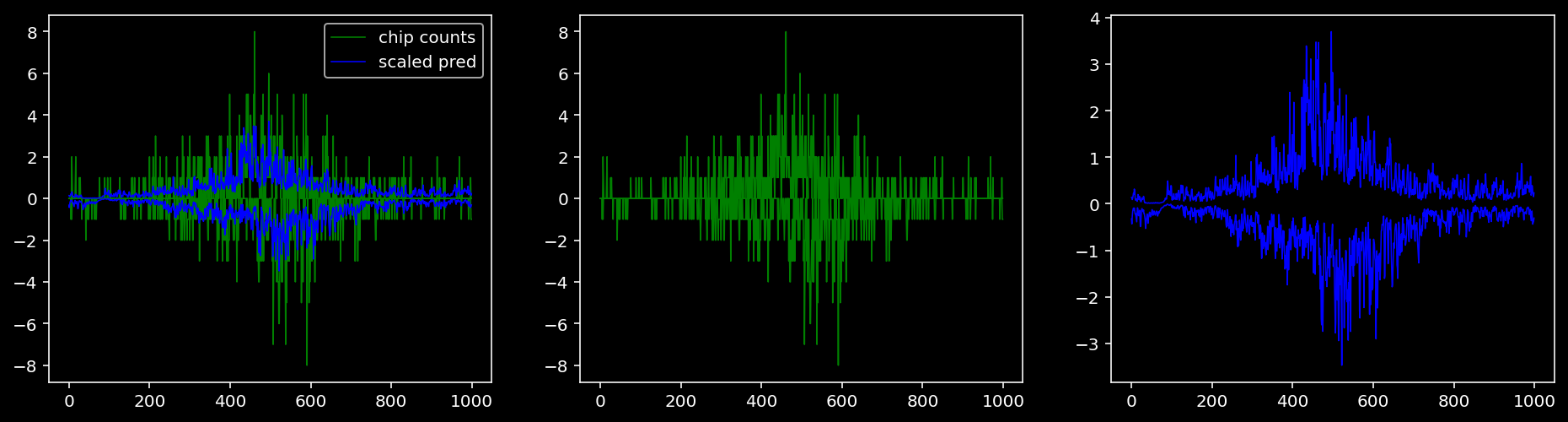
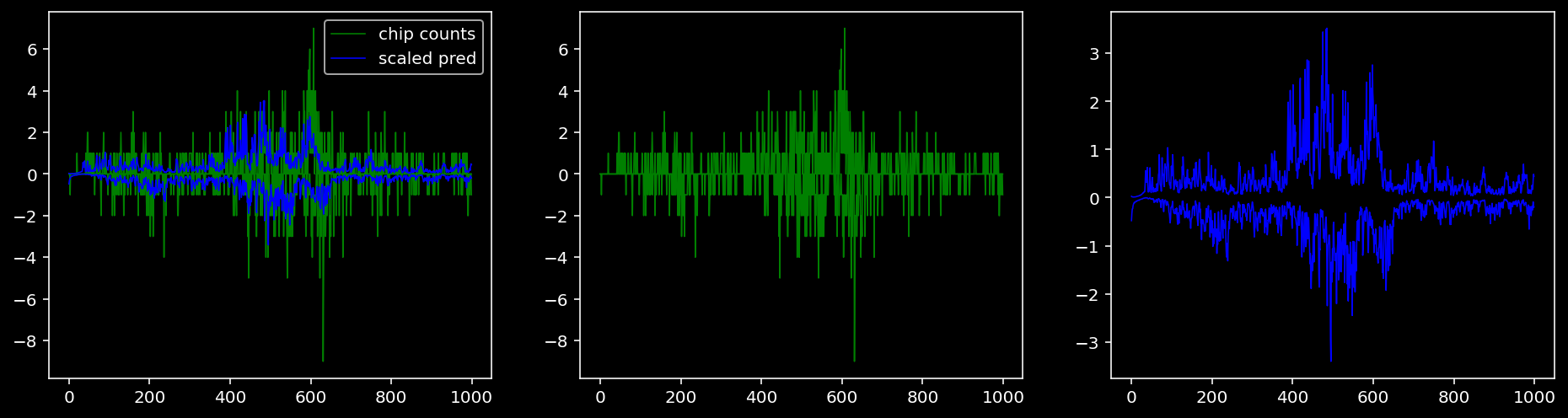
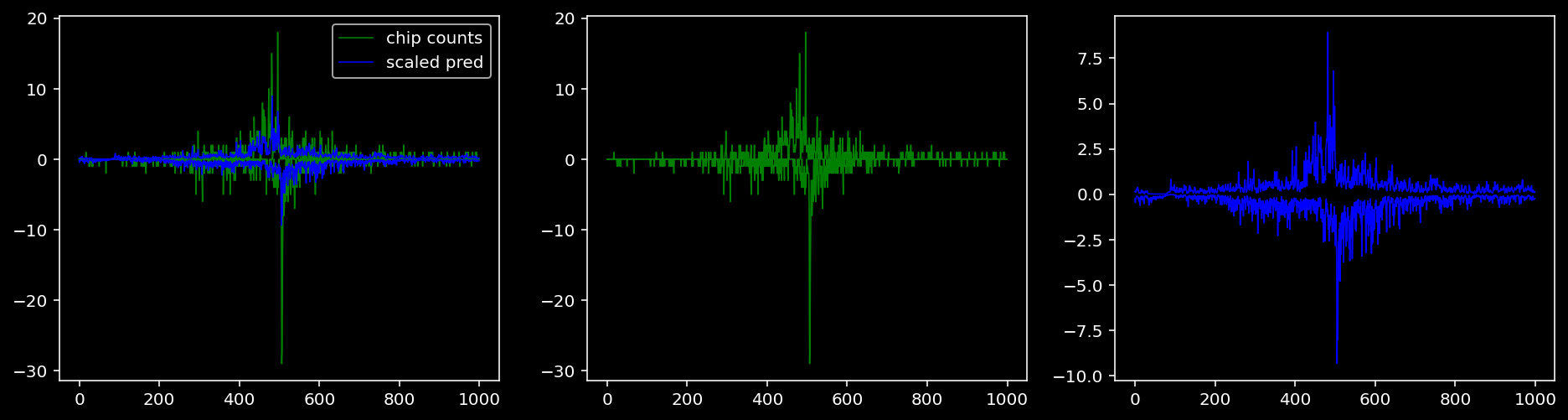
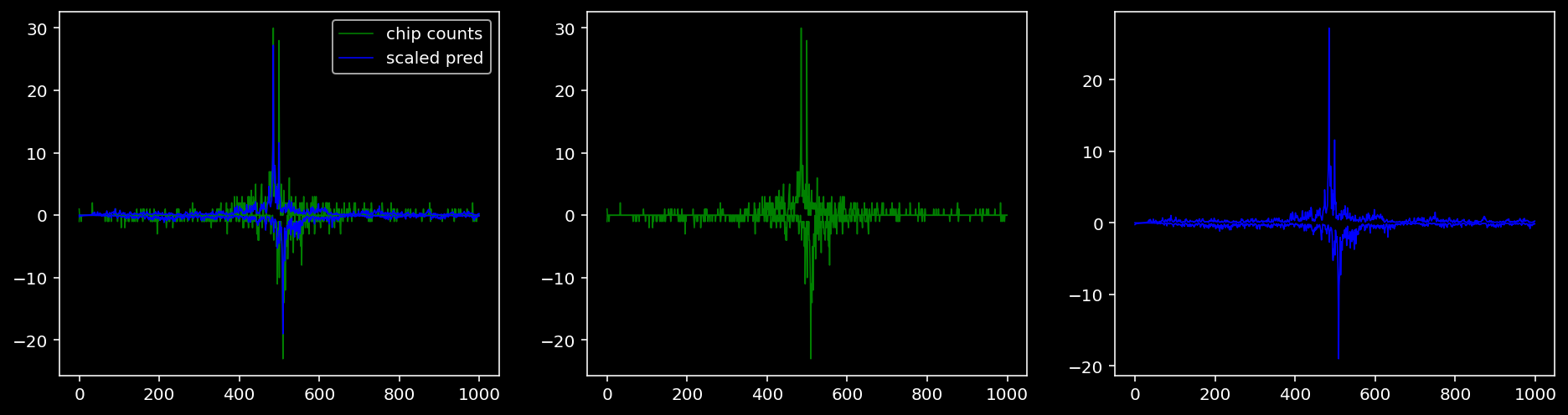
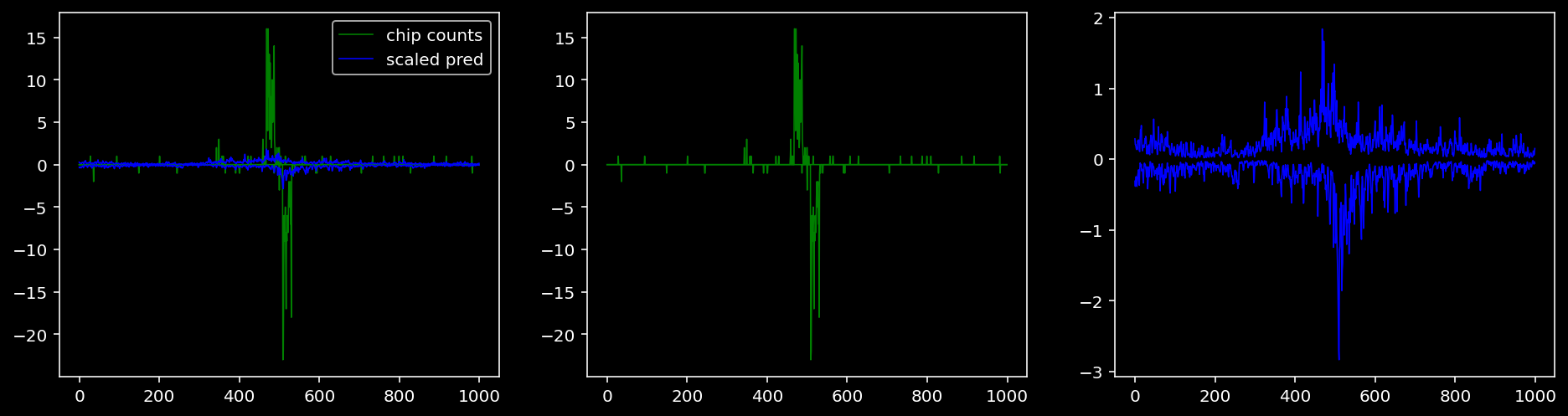
Plotting the real counts and the predictions for the first batch from the tune dataset.
tune_loader=DataLoader(tune_dataset, batch_size=10, shuffle=False, num_workers=0, pin_memory=True)
one_hot, tf_counts, ctrl_counts, ctrl_smooth = next(tune_loader.__iter__())
one_hot, tf_counts, ctrl_counts, ctrl_smooth = one_hot.to(device), tf_counts.to(device), ctrl_counts.to(device), ctrl_smooth.to(device)
profile_pred, _ = model.forward(sequence=one_hot, bias_raw=ctrl_counts, bias_smooth=ctrl_smooth)
profile_pred = profile_pred.to("cpu").detach().numpy()
tf_counts = tf_counts.to("cpu").detach().numpy()
scaled_pred = profile_pred * tf_counts.sum(axis=-1)[:,:,:,None]
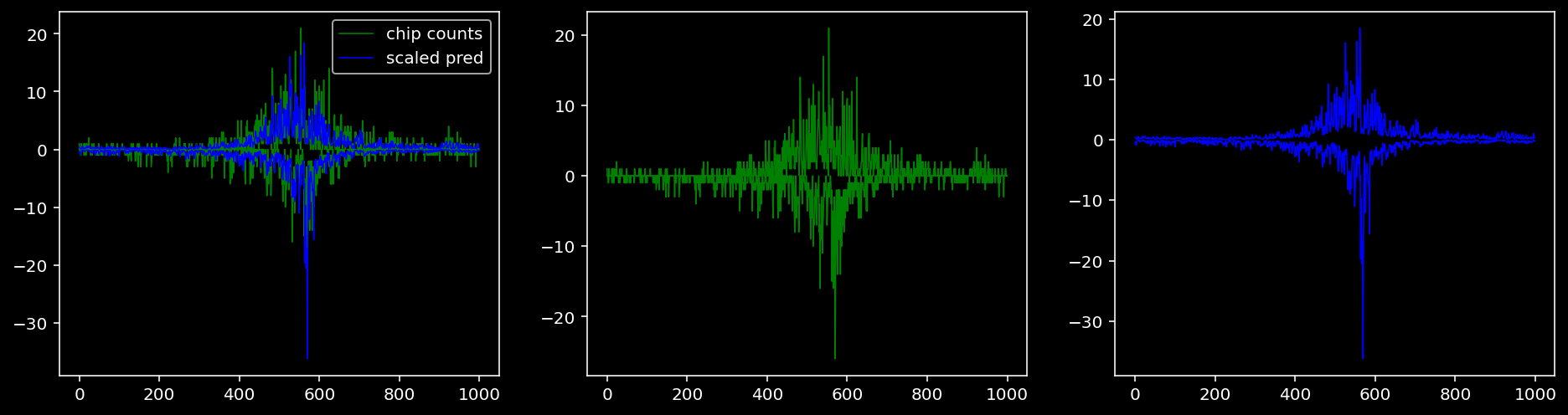
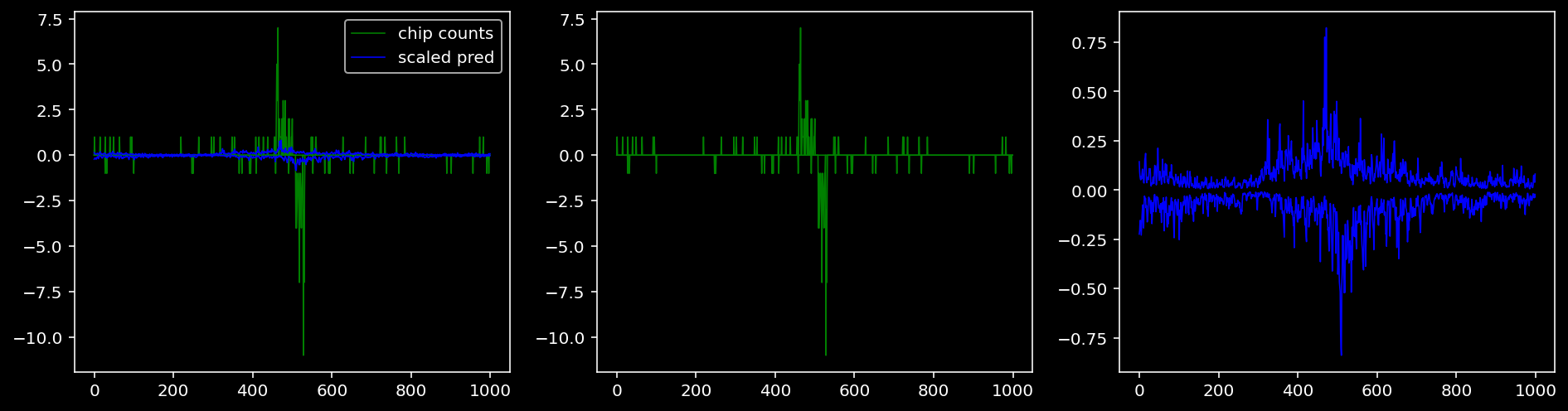
lw = 0.85.4.1.1 Specific Sequence
tmp_df = test_dataset.region_info.copy().reset_index()
idx = tmp_df.loc[(tmp_df.seqnames=="chr1") & (tmp_df.start > 180924752-1000) & (tmp_df.end < 180925152+1000) & (tmp_df.TF == "Sox2")].index.to_numpy()[0]
print(tmp_df.iloc[idx])
shape_pred, count_pred = model.forward(torch.from_numpy(test_dataset.one_hot_seqs[idx:idx+1, ]).to(device), torch.from_numpy(test_dataset.ctrl_counts[idx:idx+1, ]).to(device), torch.from_numpy(test_dataset.ctrl_counts_smooth[idx:idx+1, ]).to(device))
shape_pred = shape_pred.cpu().detach().numpy()
df = pd.DataFrame(columns=["position", "TF", "strand", "kind", "value"])
for data, kind in zip([test_dataset.tf_counts[idx], shape_pred[0]], ["counts", "prediction"]):
for i, tf in enumerate(TF_LIST):
for j, strand in enumerate(["pos", "neg"]):
tmp_df = pd.DataFrame({"position": np.arange(1000), "TF": tf, "strand": strand, "kind": kind, "value": data[i, j]})
df = df.append(tmp_df)
df.to_csv("/home/philipp/BPNet/out/example_shape_prediction.csv")index 97
seqnames chr1
start 180924435
end 180925434
width 1000
strand *
TF Sox2
set test
name NaN
score 1000
signalValue 17.39712
pValue 441.17929
qValue 436.06531
peak 404
Region chr1:180924435-180925434
Name: 19, dtype: object/tmp/ipykernel_1221851/1462060750.py:15: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)
/tmp/ipykernel_1221851/1462060750.py:15: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)
/tmp/ipykernel_1221851/1462060750.py:15: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)
/tmp/ipykernel_1221851/1462060750.py:15: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)
/tmp/ipykernel_1221851/1462060750.py:15: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)
/tmp/ipykernel_1221851/1462060750.py:15: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)
/tmp/ipykernel_1221851/1462060750.py:15: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)
/tmp/ipykernel_1221851/1462060750.py:15: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)
/tmp/ipykernel_1221851/1462060750.py:15: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)
/tmp/ipykernel_1221851/1462060750.py:15: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)
/tmp/ipykernel_1221851/1462060750.py:15: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)
/tmp/ipykernel_1221851/1462060750.py:15: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)
/tmp/ipykernel_1221851/1462060750.py:15: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)
/tmp/ipykernel_1221851/1462060750.py:15: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)
/tmp/ipykernel_1221851/1462060750.py:15: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)
/tmp/ipykernel_1221851/1462060750.py:15: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)5.4.1.2 Nanog
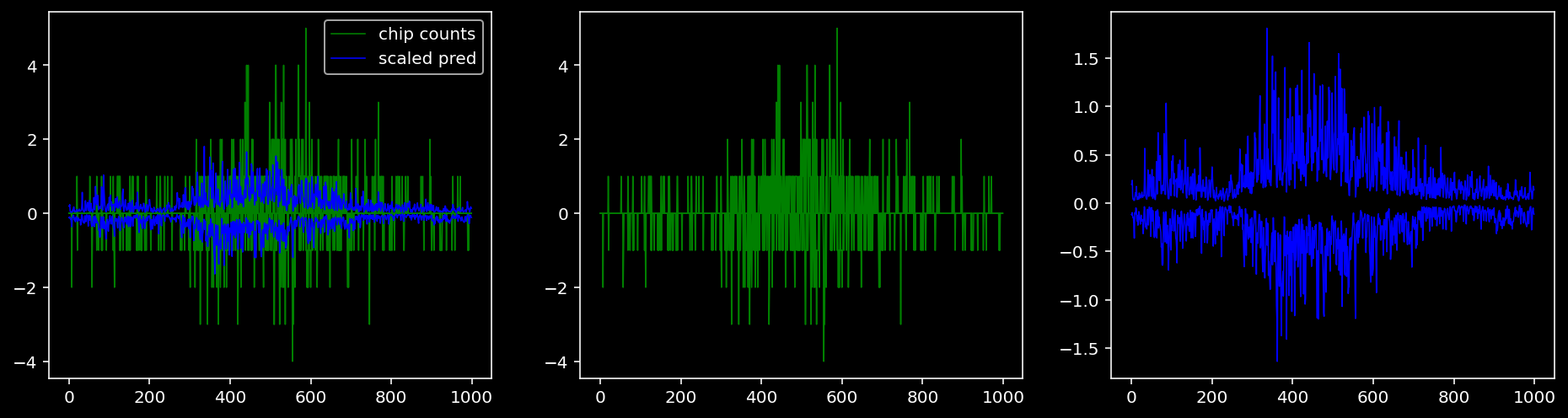
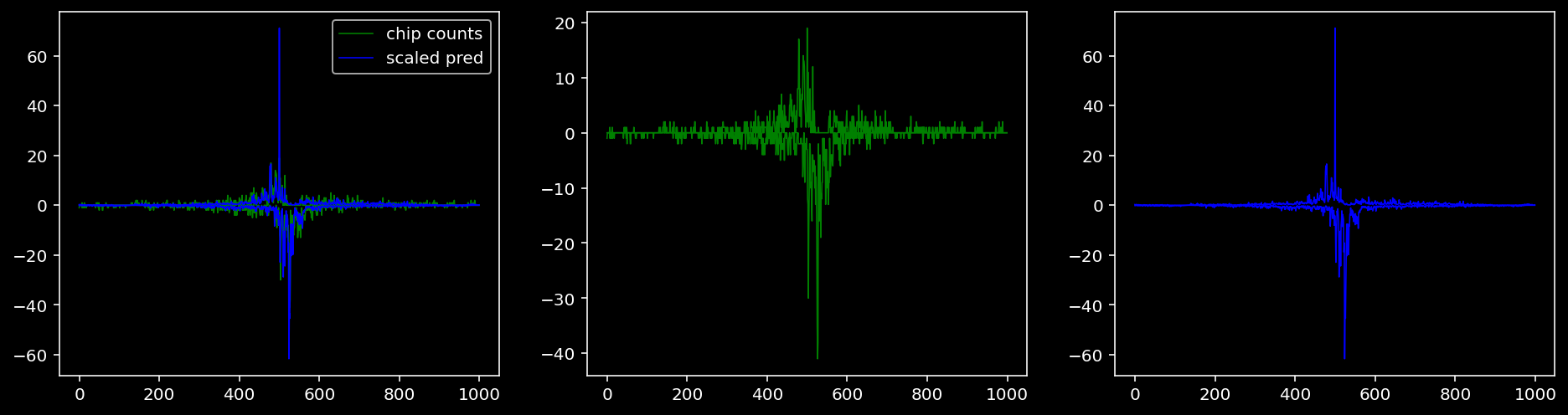
tf = 0
for i in range(profile_pred.shape[0]):
fig, axis = plt.subplots(1, 3, figsize=(16, 4))
axis[0].plot(tf_counts[i, tf, 0], label="chip counts", color="green", linewidth=lw)
axis[0].plot(-tf_counts[i, tf, 1], color="green", linewidth=lw)
axis[1].plot(tf_counts[i, tf, 0], label="chip counts", color="green", linewidth=lw)
axis[1].plot(-tf_counts[i, tf, 1], color="green", linewidth=lw)
axis[0].plot(scaled_pred[i, tf, 0], label="scaled pred", color="blue", linewidth=lw)
axis[0].plot(-scaled_pred[i, tf, 1], color="blue", linewidth=lw)
axis[2].plot(scaled_pred[i, tf, 0], label="scaled pred", color="blue", linewidth=lw)
axis[2].plot(-scaled_pred[i, tf, 1], color="blue", linewidth=lw)
axis[0].legend()
plt.show()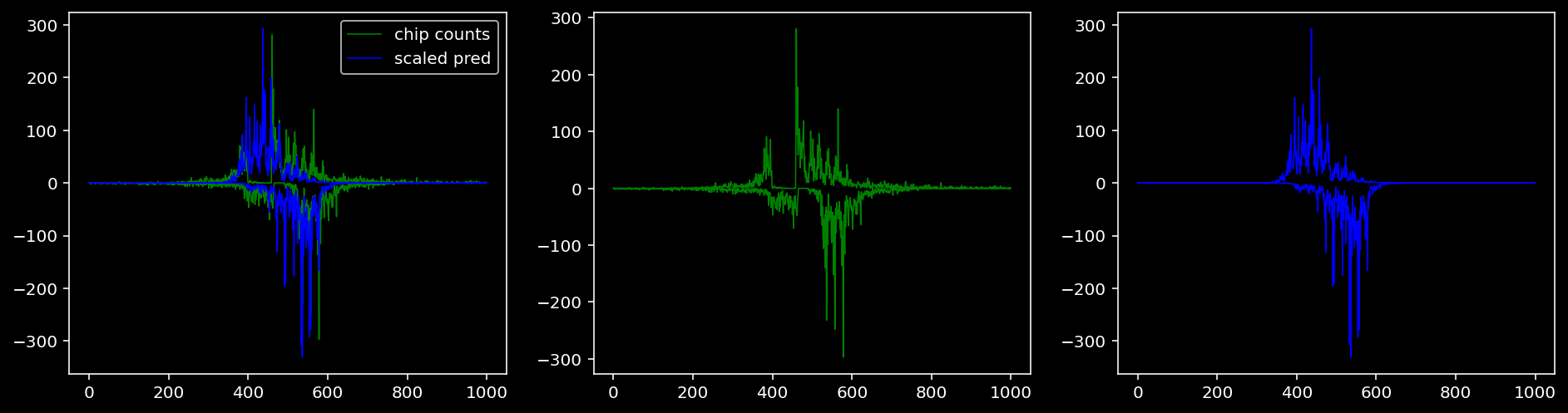
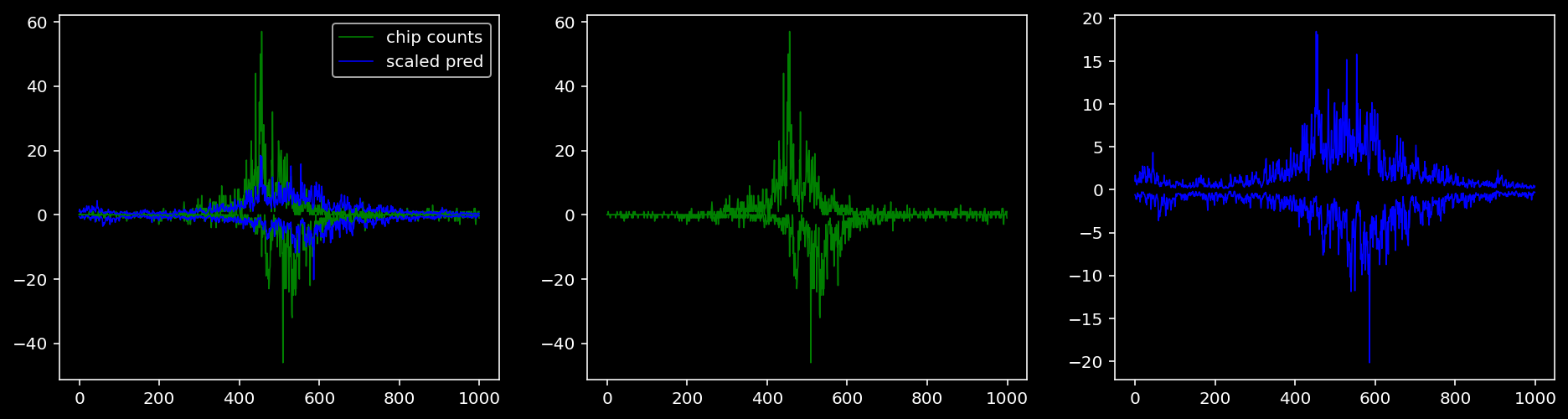
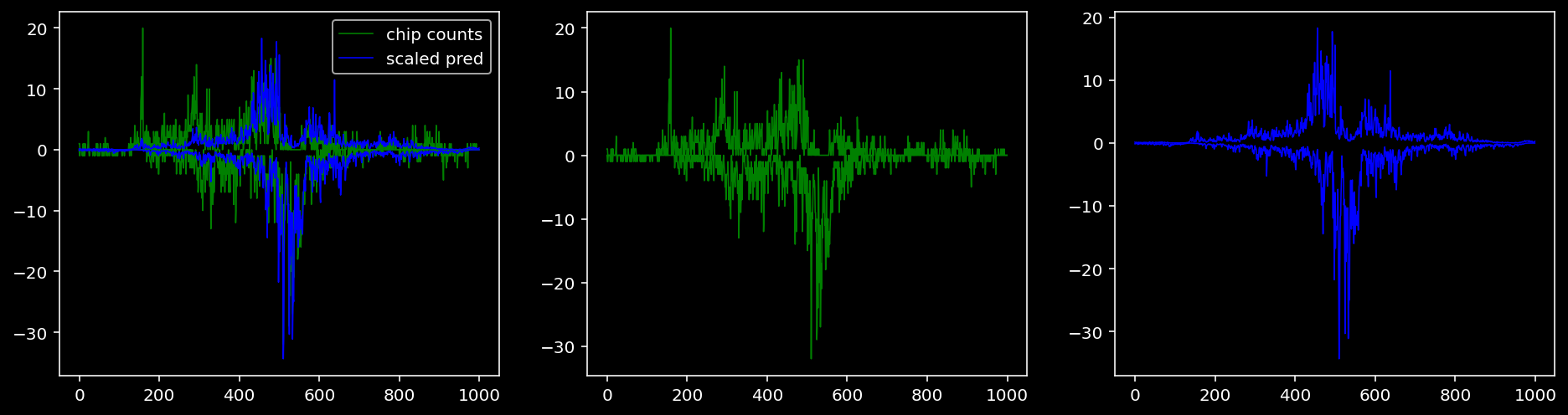
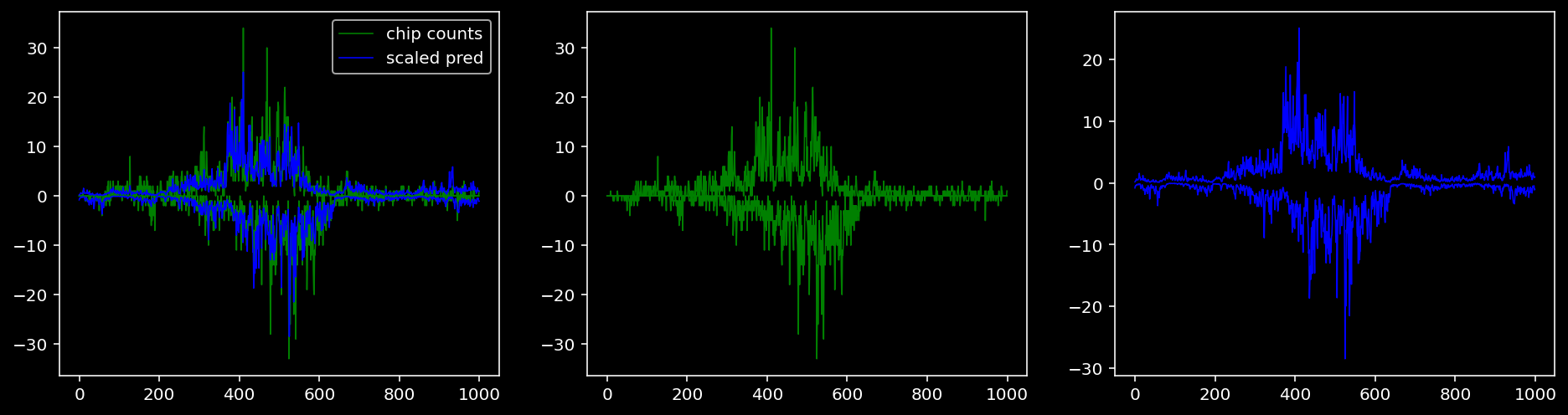
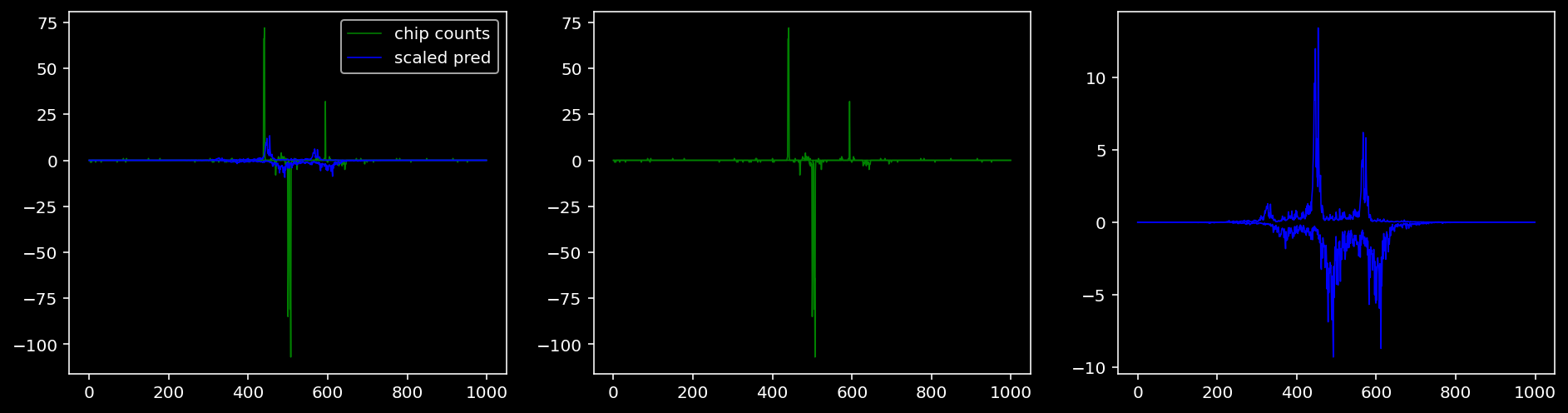
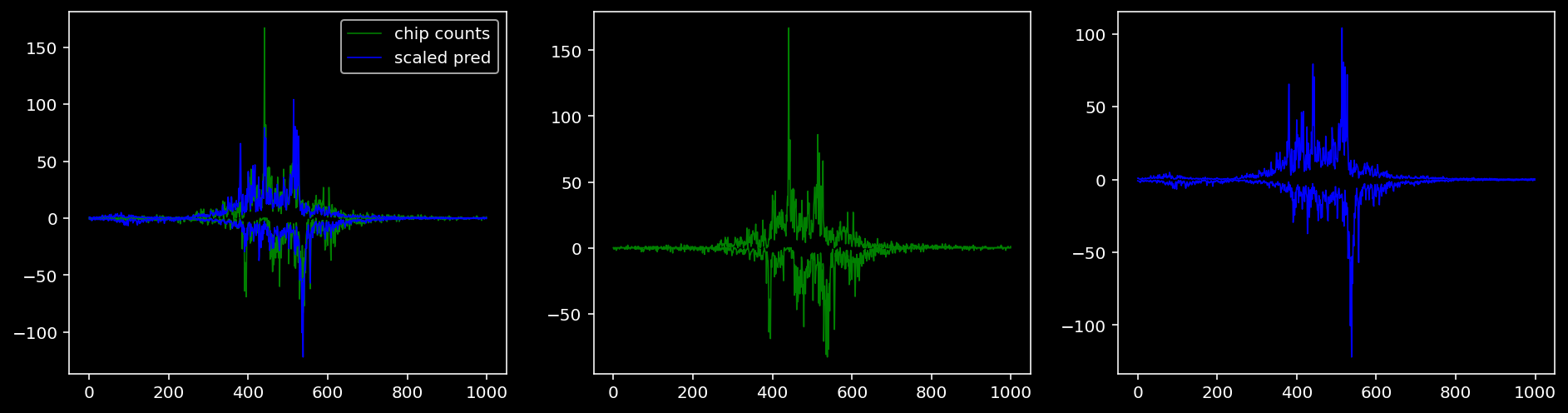
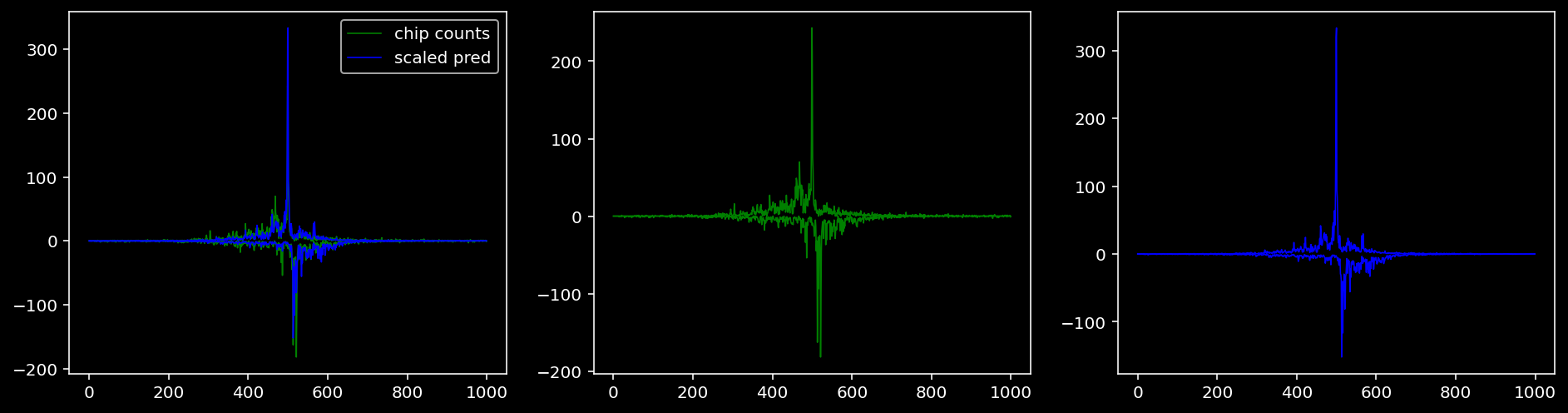
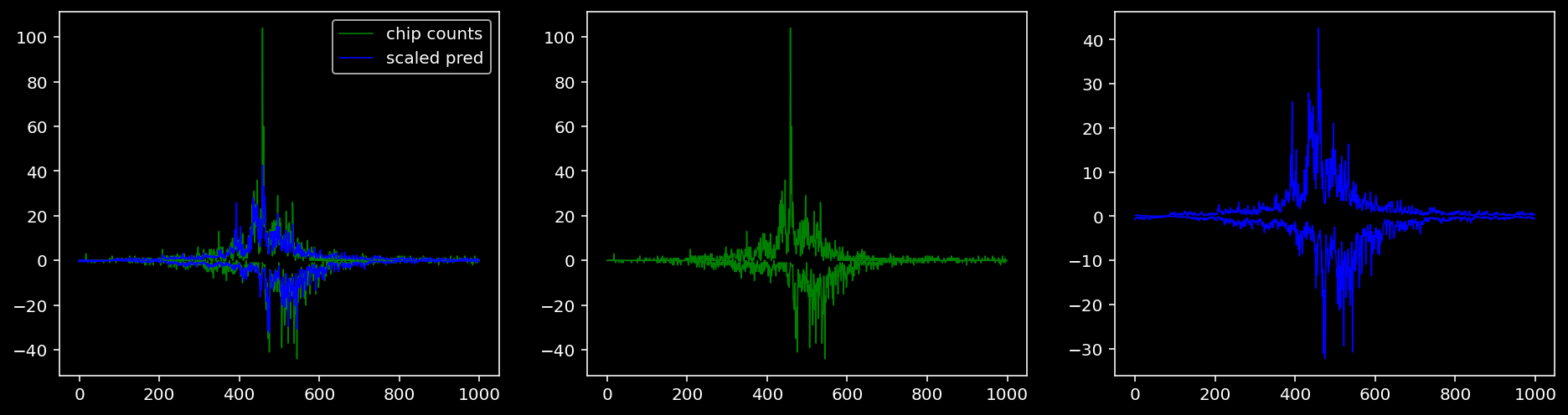
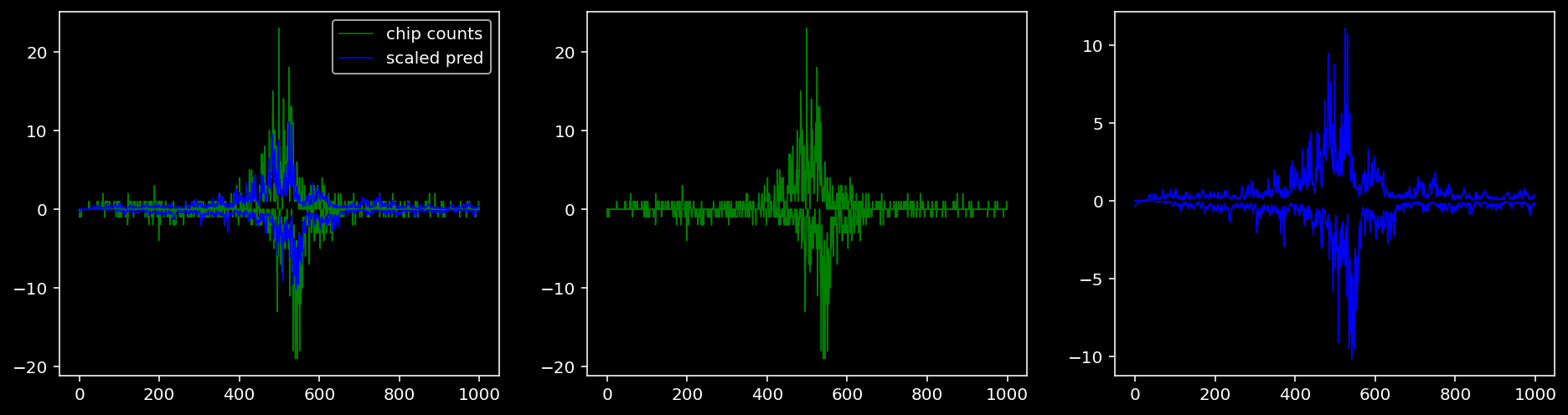
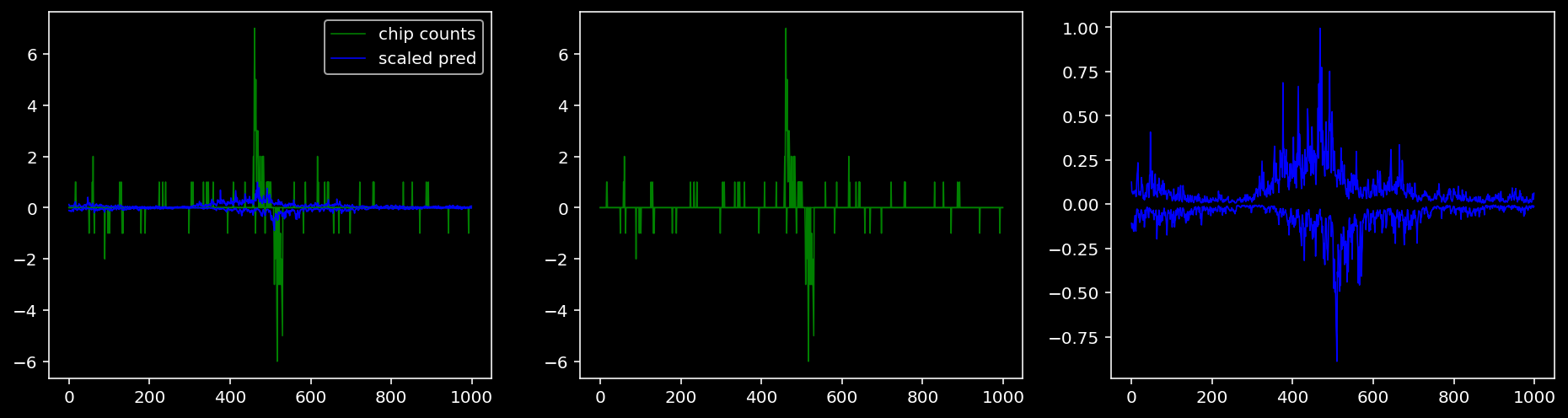
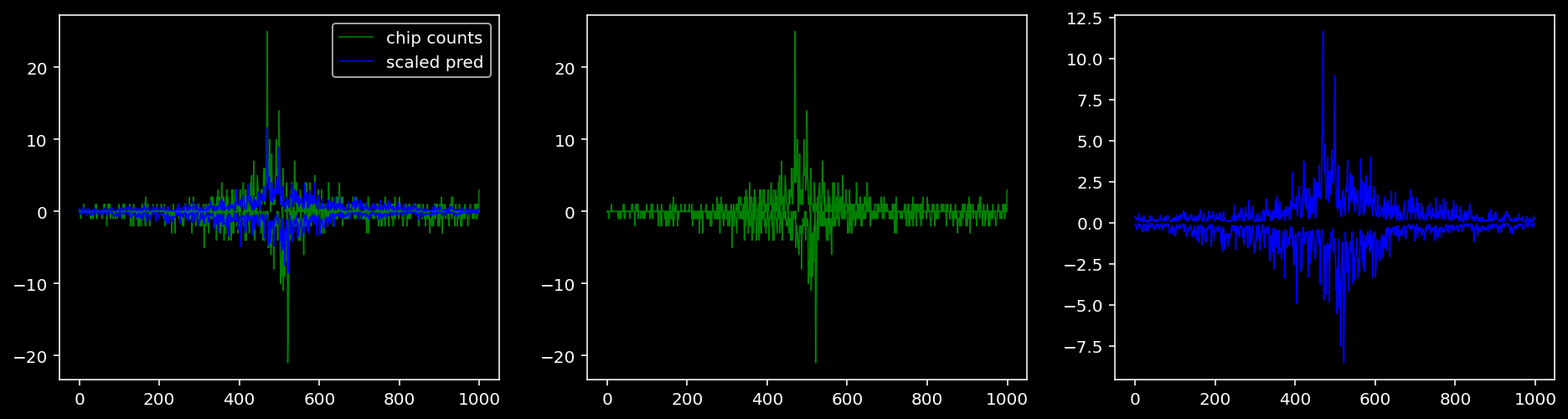
5.4.1.3 Klf4
tf = 1
for i in range(profile_pred.shape[0]):
fig, axis = plt.subplots(1, 3, figsize=(16, 4))
axis[0].plot(tf_counts[i, tf, 0], label="chip counts", color="green", linewidth=lw)
axis[0].plot(-tf_counts[i, tf, 1], color="green", linewidth=lw)
axis[1].plot(tf_counts[i, tf, 0], label="chip counts", color="green", linewidth=lw)
axis[1].plot(-tf_counts[i, tf, 1], color="green", linewidth=lw)
axis[0].plot(scaled_pred[i, tf, 0], label="scaled pred", color="blue", linewidth=lw)
axis[0].plot(-scaled_pred[i, tf, 1], color="blue", linewidth=lw)
axis[2].plot(scaled_pred[i, tf, 0], label="scaled pred", color="blue", linewidth=lw)
axis[2].plot(-scaled_pred[i, tf, 1], color="blue", linewidth=lw)
axis[0].legend()
plt.show()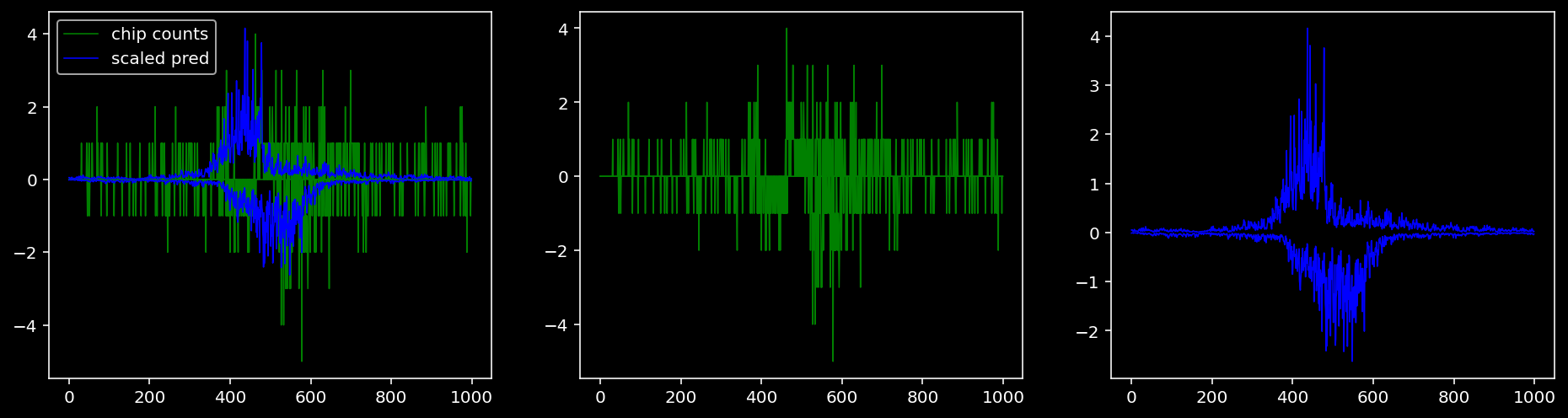
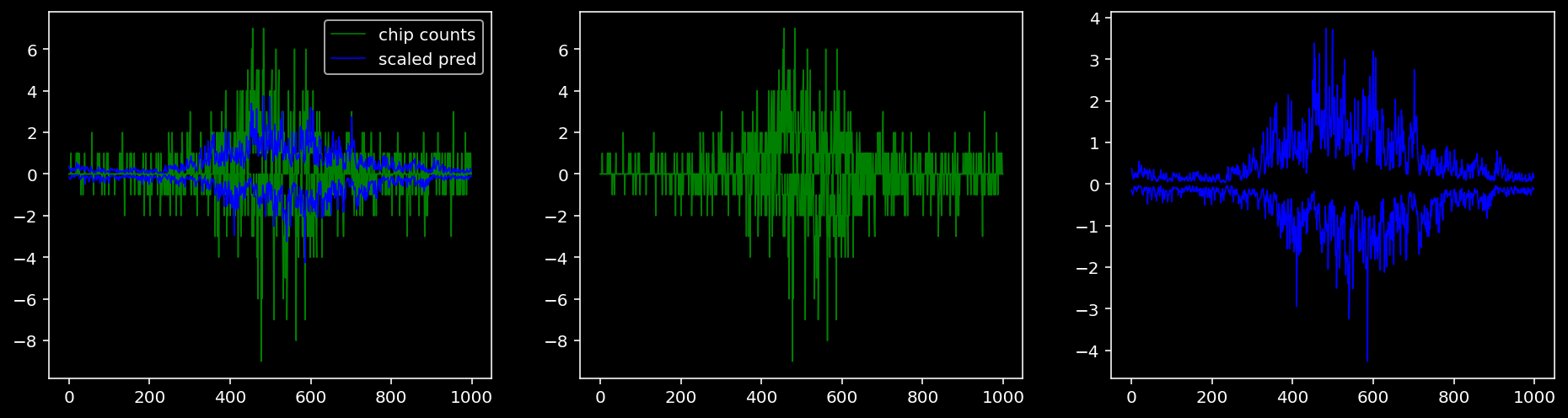
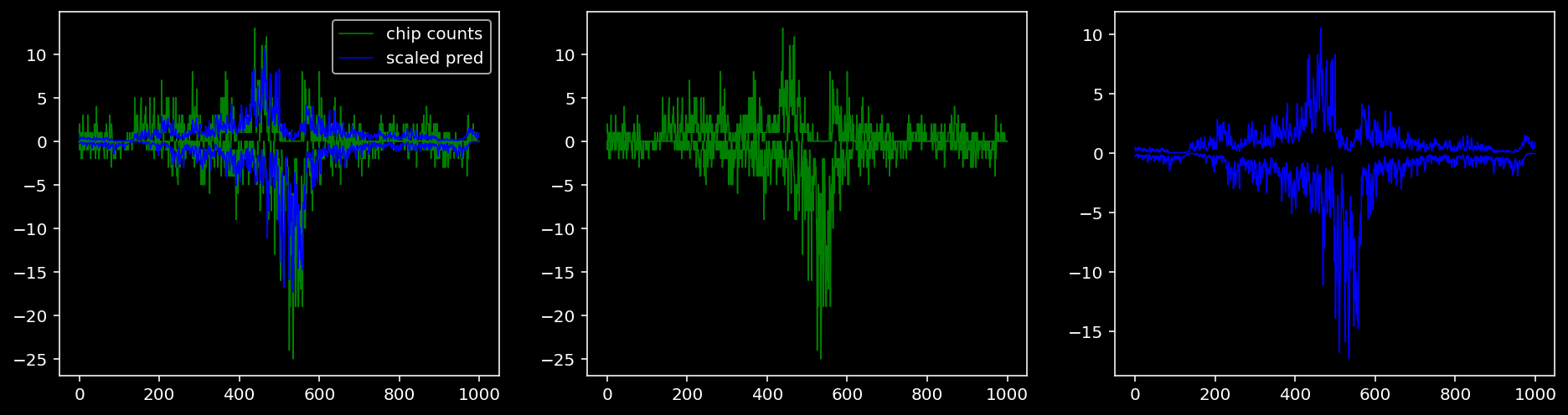
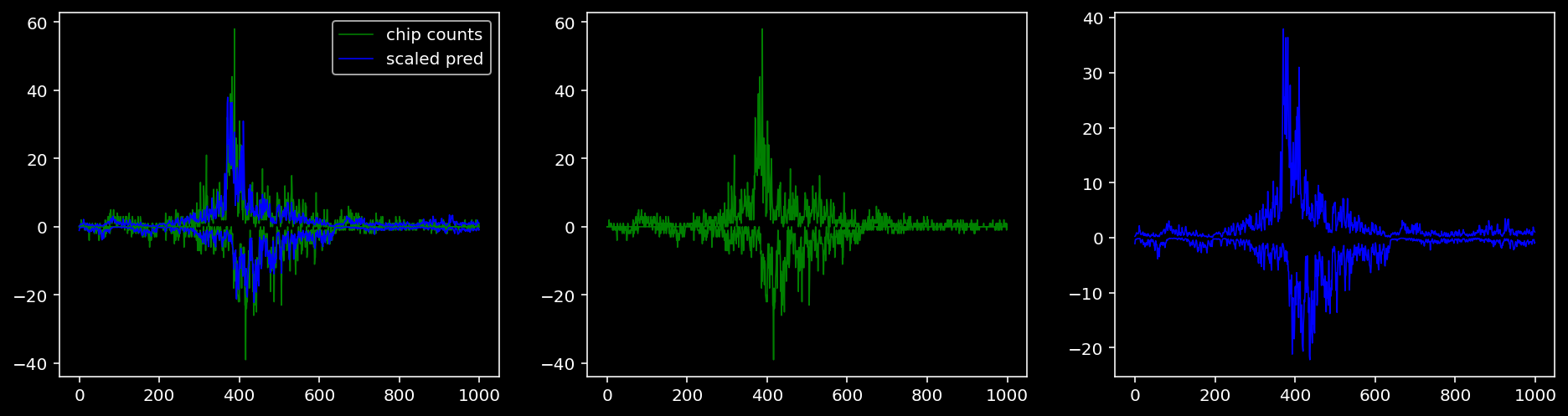
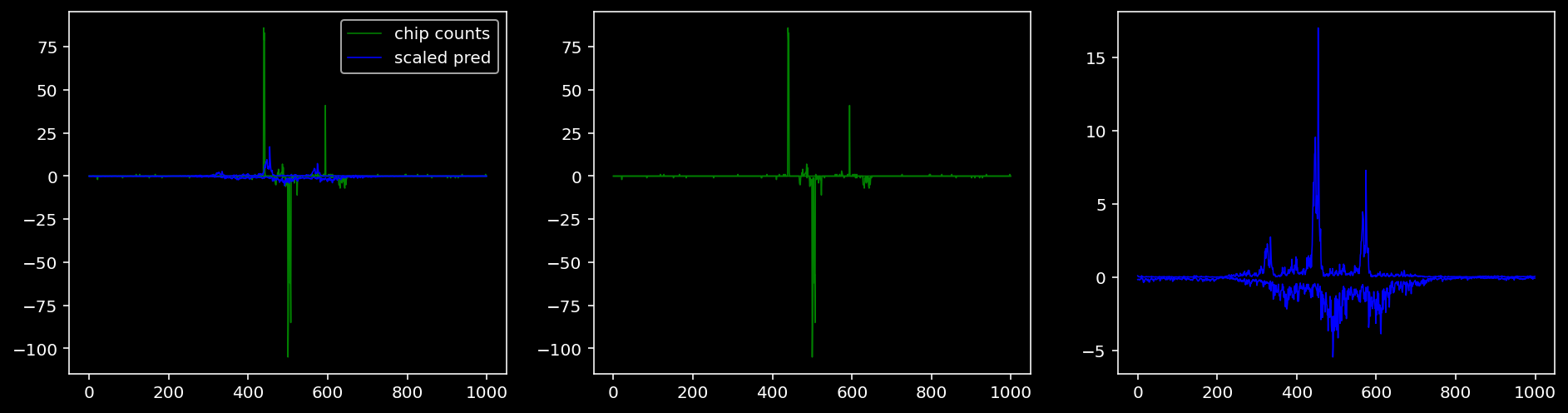
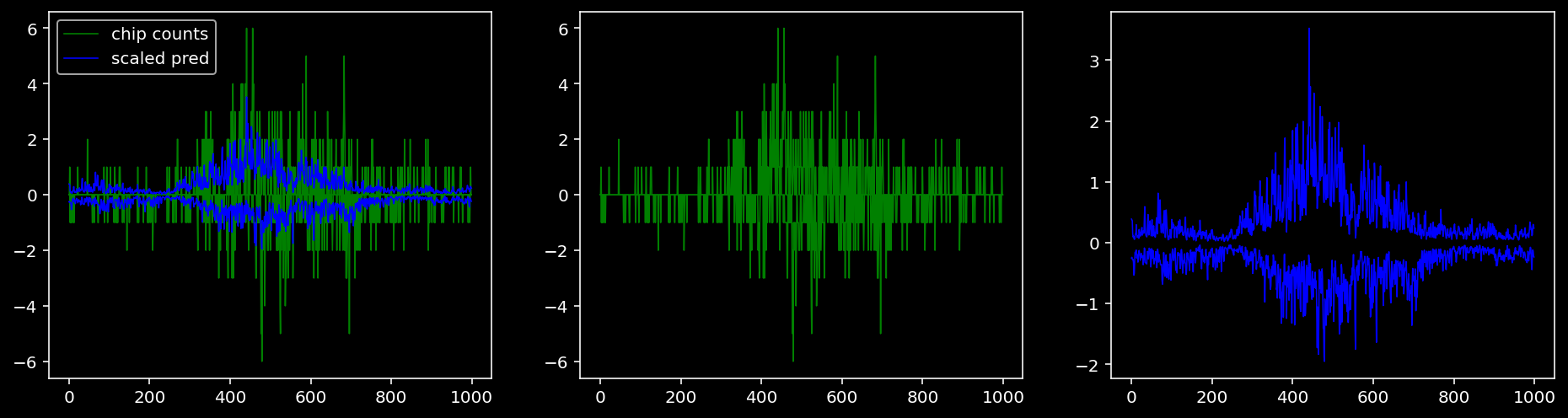
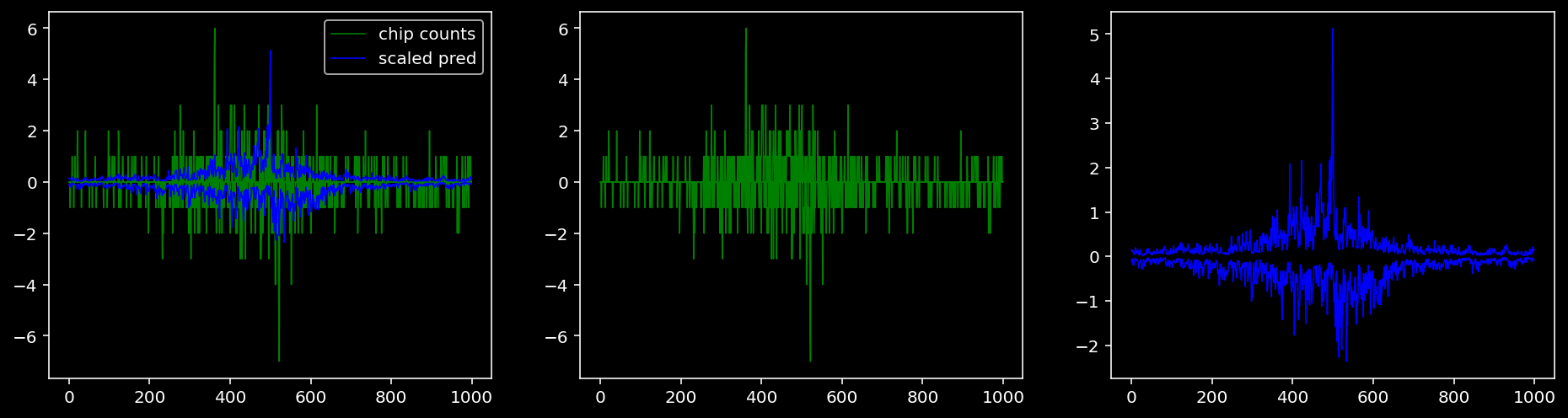
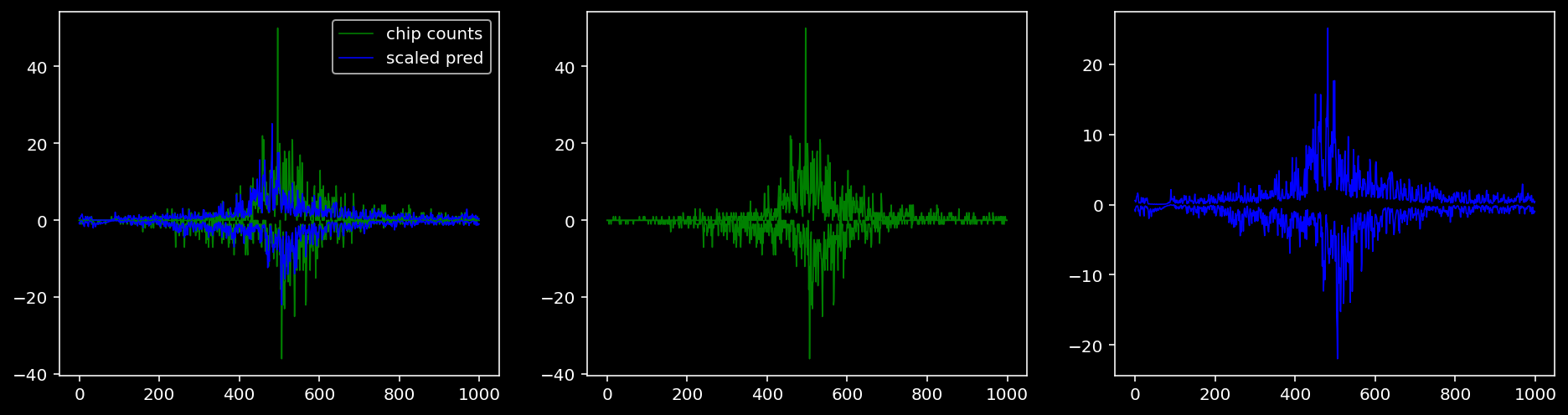
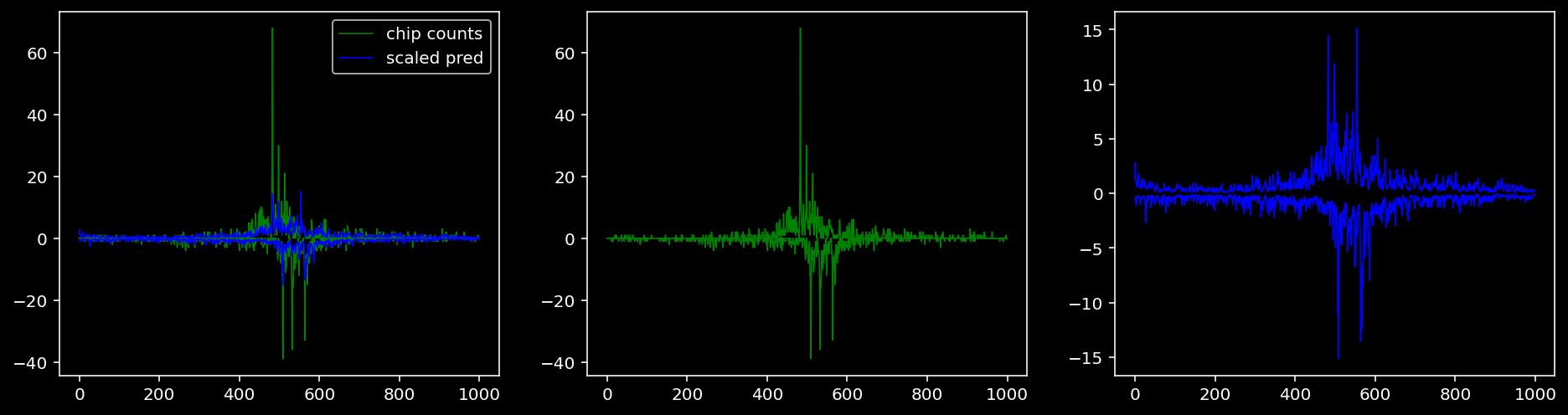
5.4.1.4 Oct4
tf = 2
for i in range(profile_pred.shape[0]):
fig, axis = plt.subplots(1, 3, figsize=(16, 4))
axis[0].plot(tf_counts[i, tf, 0], label="chip counts", color="green", linewidth=lw)
axis[0].plot(-tf_counts[i, tf, 1], color="green", linewidth=lw)
axis[1].plot(tf_counts[i, tf, 0], label="chip counts", color="green", linewidth=lw)
axis[1].plot(-tf_counts[i, tf, 1], color="green", linewidth=lw)
axis[0].plot(scaled_pred[i, tf, 0], label="scaled pred", color="blue", linewidth=lw)
axis[0].plot(-scaled_pred[i, tf, 1], color="blue", linewidth=lw)
axis[2].plot(scaled_pred[i, tf, 0], label="scaled pred", color="blue", linewidth=lw)
axis[2].plot(-scaled_pred[i, tf, 1], color="blue", linewidth=lw)
axis[0].legend()
plt.show()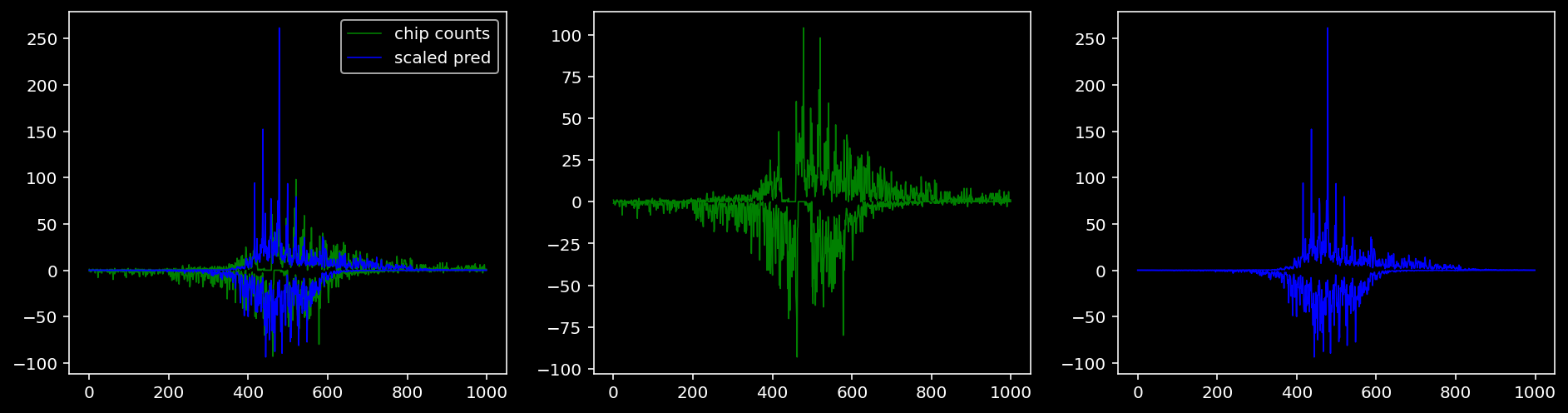
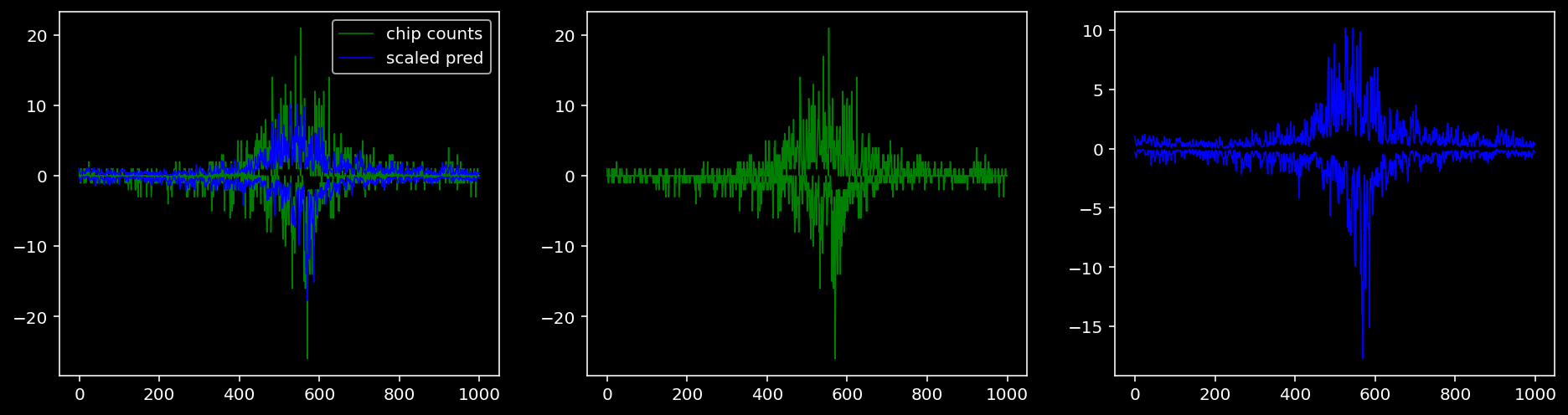
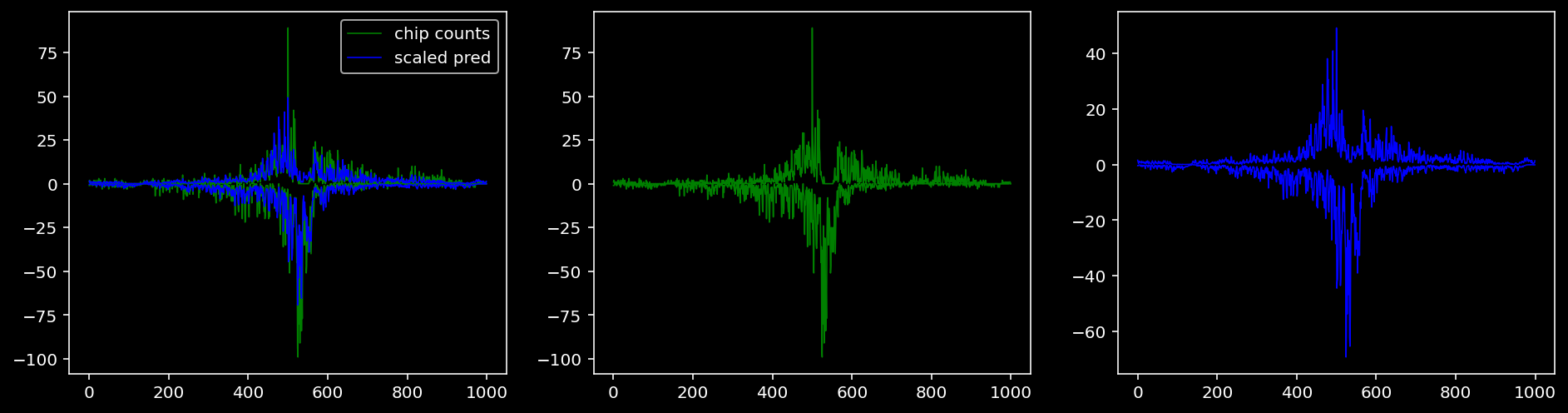
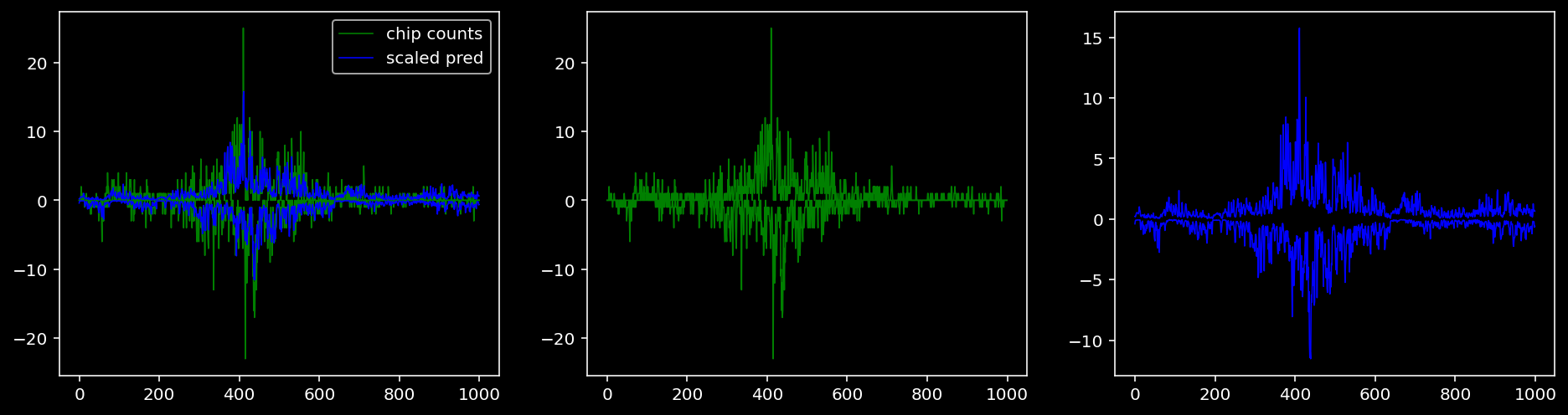
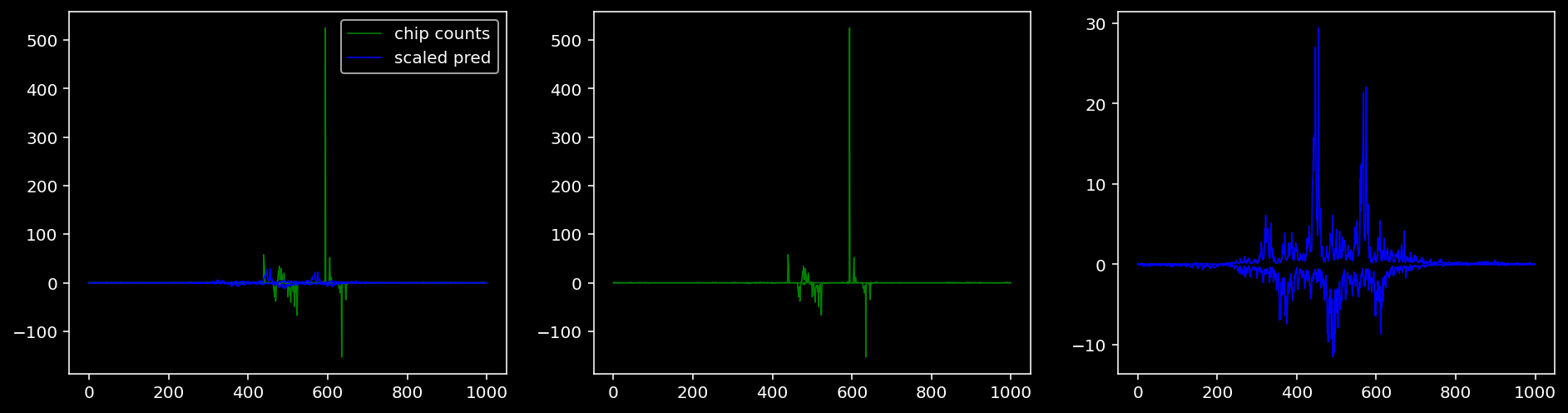
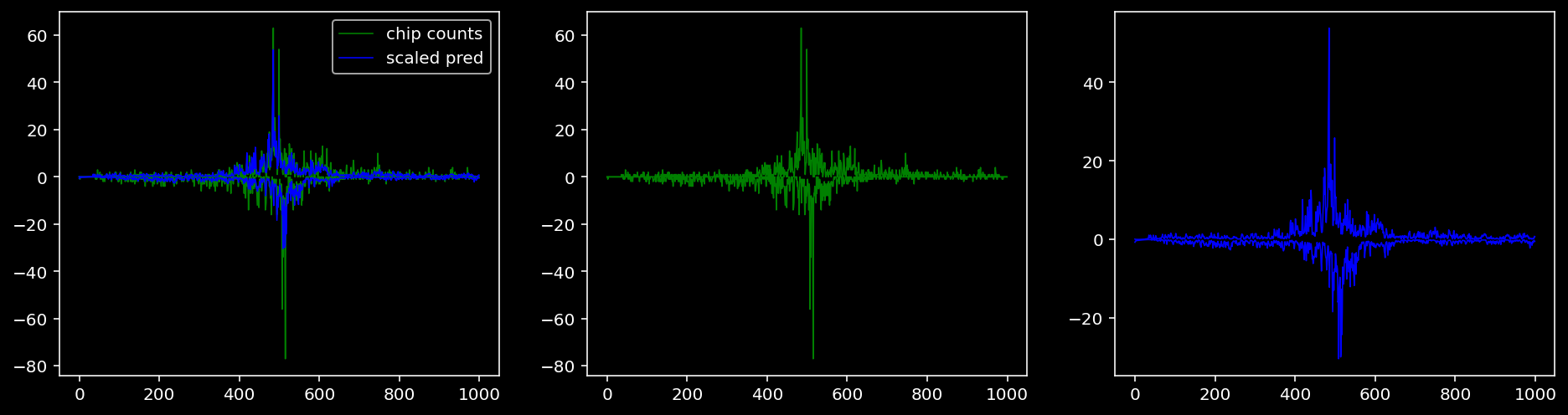
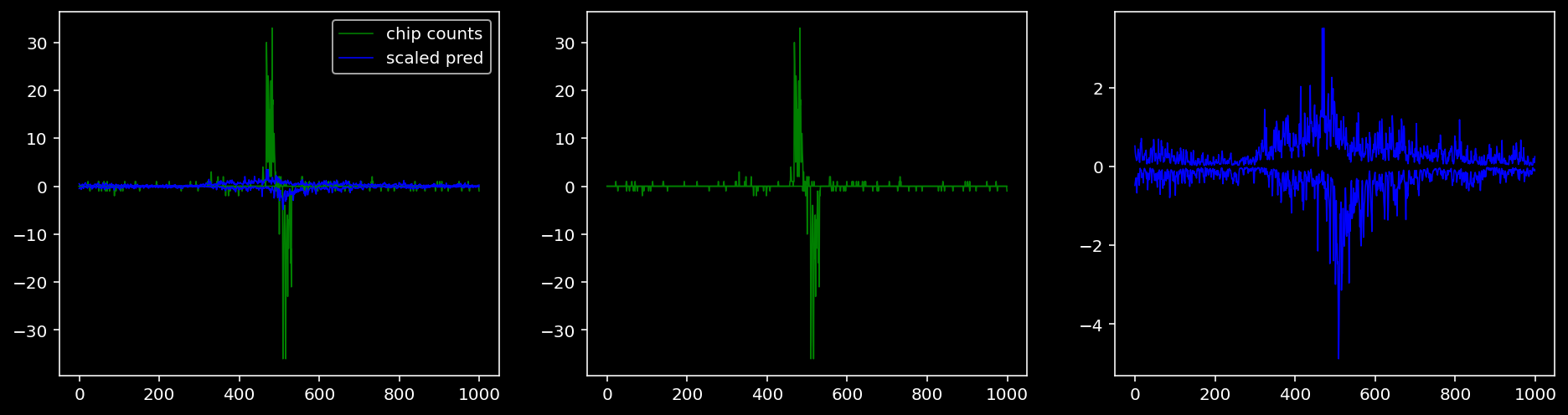
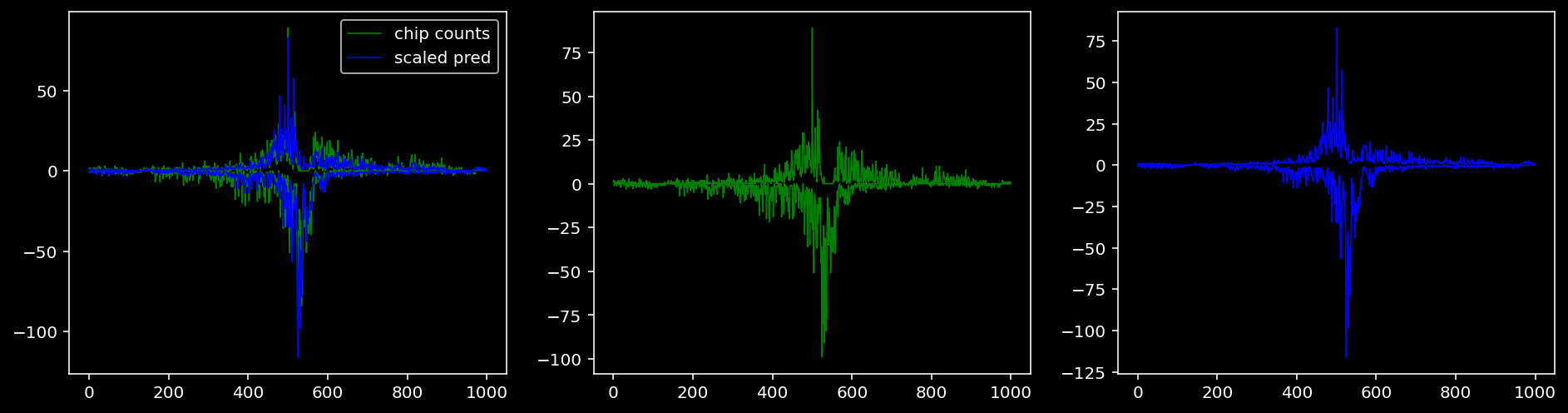
5.4.1.5 Sox2
tf = 3
for i in range(profile_pred.shape[0]):
fig, axis = plt.subplots(1, 3, figsize=(16, 4))
axis[0].plot(tf_counts[i, tf, 0], label="chip counts", color="green", linewidth=lw)
axis[0].plot(-tf_counts[i, tf, 1], color="green", linewidth=lw)
axis[1].plot(tf_counts[i, tf, 0], label="chip counts", color="green", linewidth=lw)
axis[1].plot(-tf_counts[i, tf, 1], color="green", linewidth=lw)
axis[0].plot(scaled_pred[i, tf, 0], label="scaled pred", color="blue", linewidth=lw)
axis[0].plot(-scaled_pred[i, tf, 1], color="blue", linewidth=lw)
axis[2].plot(scaled_pred[i, tf, 0], label="scaled pred", color="blue", linewidth=lw)
axis[2].plot(-scaled_pred[i, tf, 1], color="blue", linewidth=lw)
axis[0].legend()
plt.show()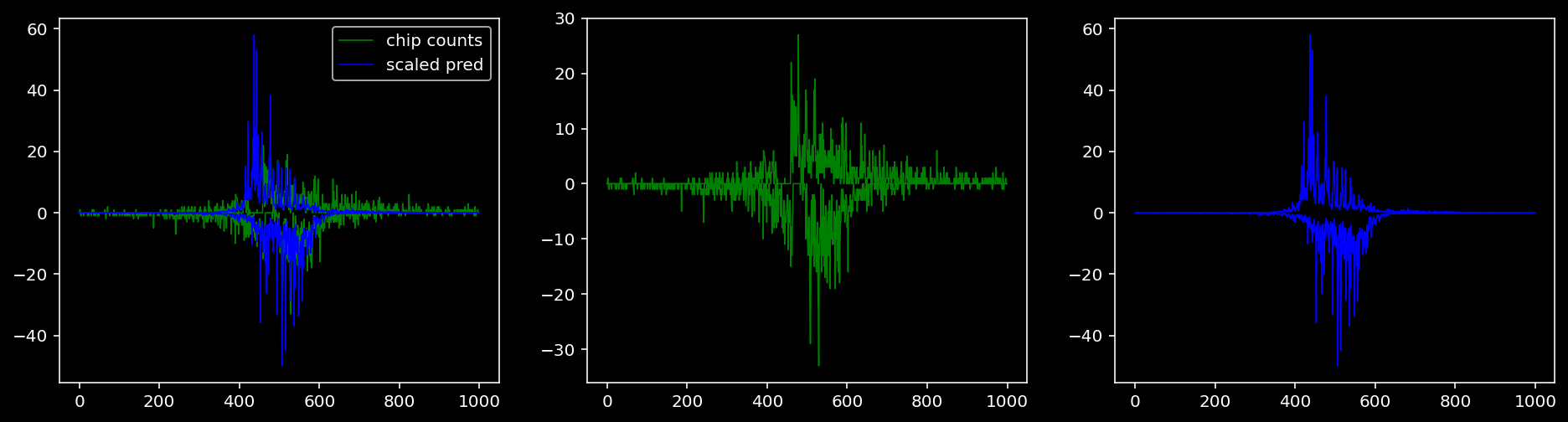
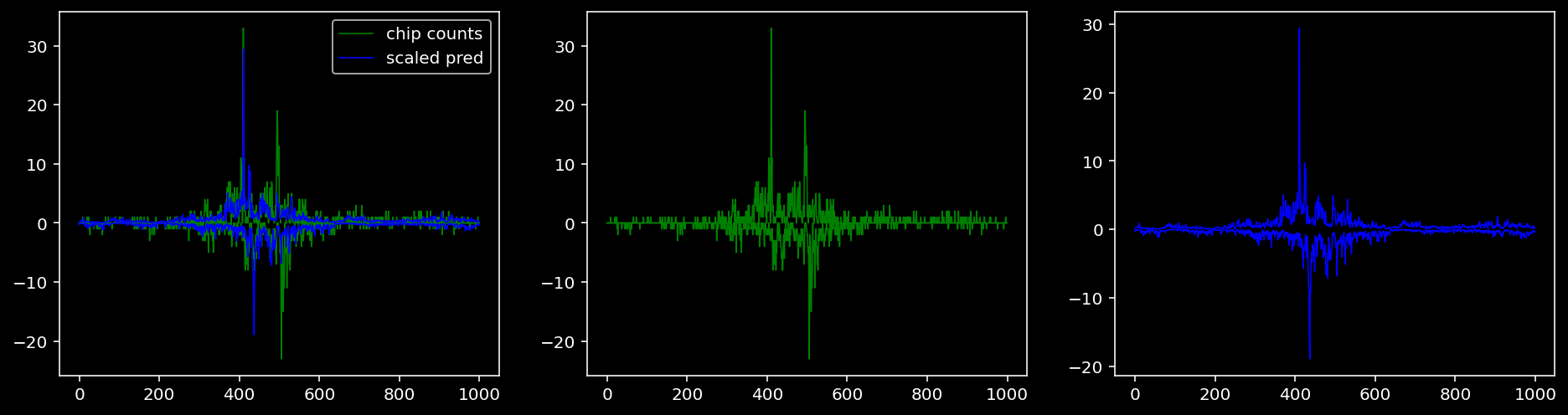
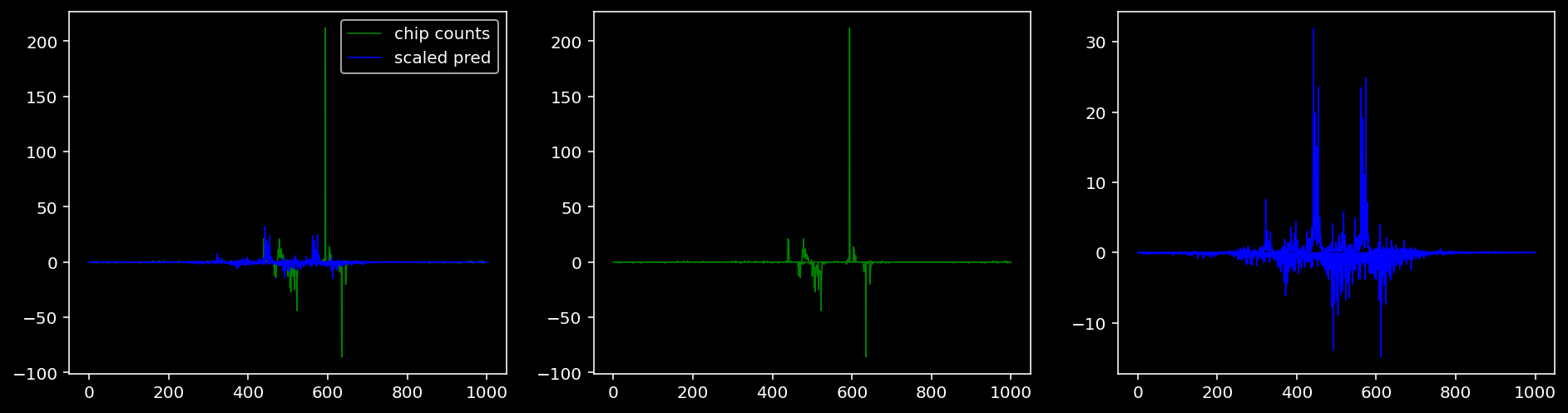
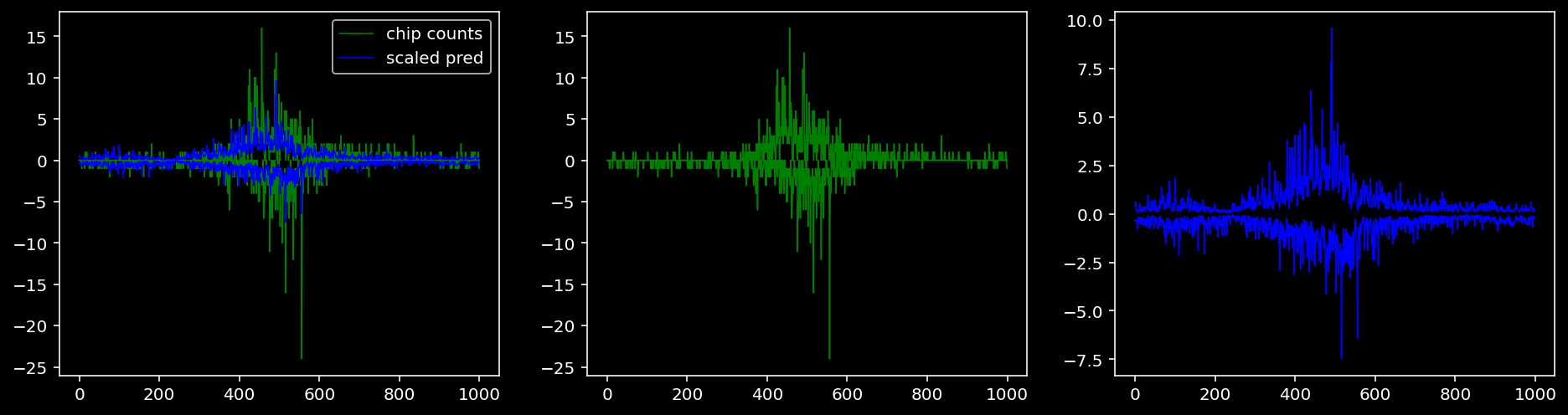
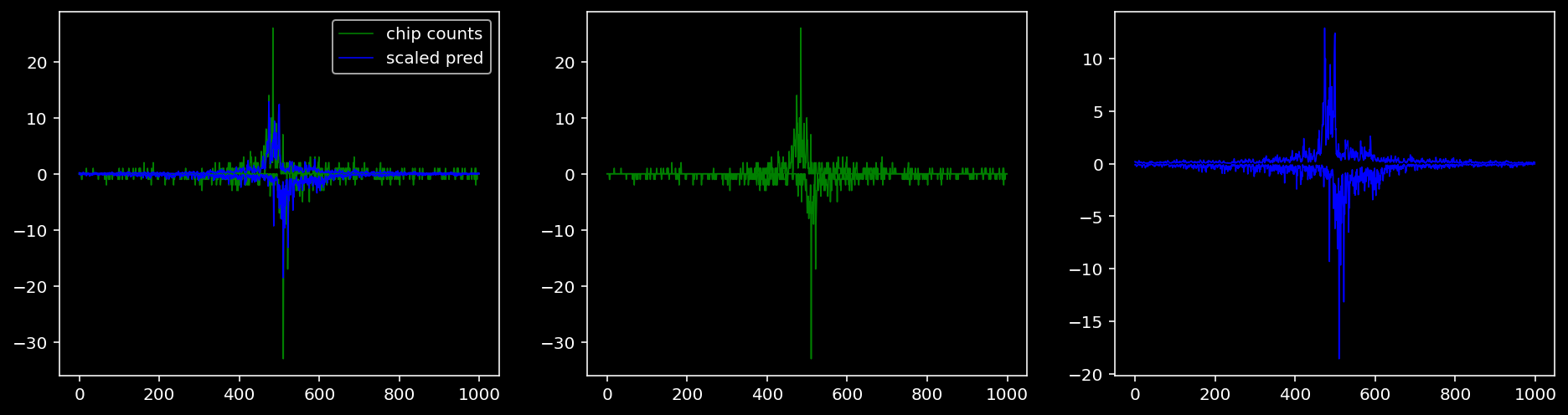
5.4.2 Precision and Recall
test_pred = torch.zeros(test_dataset.tf_counts.shape, dtype=torch.float32).to(device)
test_count_pred = torch.zeros(test_dataset.tf_counts.shape[0:3], dtype=torch.float32).to(device)
with torch.no_grad():
for batch_idx, data in enumerate(test_dataloader):
#print(batch_idx, batch_idx + 100)#, data)
one_hot, tf_counts, ctrl_counts, ctrl_smooth = data
one_hot, tf_counts, ctrl_counts, ctrl_smooth = one_hot.to(device), tf_counts.to(device), ctrl_counts.to(device), ctrl_smooth.to(device)
profile_pred, count_pred = model.forward(sequence=one_hot, bias_raw=ctrl_counts, bias_smooth=ctrl_smooth)
#print(profile_pred.shape)
start = batch_idx*BATCH_SIZE
end = (batch_idx+1)*BATCH_SIZE if (batch_idx+1)*BATCH_SIZE < test_dataset.tf_counts.shape[0] else test_dataset.tf_counts.shape[0]
test_pred[start:end] = profile_pred
test_count_pred[start:end] = count_preddef plot_prc(test_dataset, test_pred, tf_index, tf_name, plot = True):
true_counts = test_dataset.tf_counts.copy()
#subset for one tf
tf_counts = true_counts[:, tf_index, :, :]
test_pred = test_pred.cpu().numpy().copy()
assert np.allclose(test_pred.sum(axis=-1), 1)
# subset for one tf
tf_pred = test_pred[:, tf_index, :, :]
binary_labels, pred_subset, random = binary_labels_from_counts(tf_counts, tf_pred, verbose=False)
precision, recall, thresholds = skm.precision_recall_curve(binary_labels, pred_subset)
if plot:
plt.plot(recall, precision, label=f"{tf}")
plt.title(f"Precision-Recall Curve: {tf_name}")
plt.xlabel("recall")
plt.ylabel("precision")
else:
return precision, recall, thresholdsfor i, tf in enumerate(TF_LIST):
plot_prc(test_dataset, test_pred, i, tf, plot=True)
plt.legend()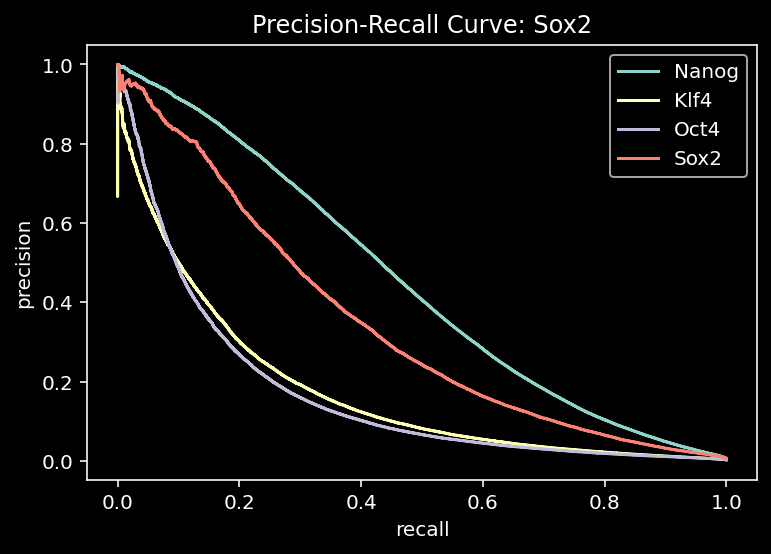
df = pd.DataFrame(columns=["TF", "precision", "recall"])
for i, tf in enumerate(TF_LIST):
precision, recall, thresholds = plot_prc(test_dataset, test_pred, i, tf, plot=False)
tmp_df = pd.DataFrame({
"TF": tf,
"precision": precision,
"recall": recall,
})
df = df.append(tmp_df)
df.to_csv("/home/philipp/BPNet/out/pr_curve_all_tfs_count_model.csv", index=False)
del df, tmp_df/tmp/ipykernel_1221851/4023111080.py:9: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)/tmp/ipykernel_1221851/4023111080.py:9: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)/tmp/ipykernel_1221851/4023111080.py:9: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)/tmp/ipykernel_1221851/4023111080.py:9: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df = df.append(tmp_df)# loop over all four TFs:
true_counts = test_dataset.tf_counts.copy()
all_pred = test_pred.cpu().numpy().copy()
patchcap = test_dataset.ctrl_counts.copy()
assert np.allclose(all_pred.sum(axis=-1), 1)
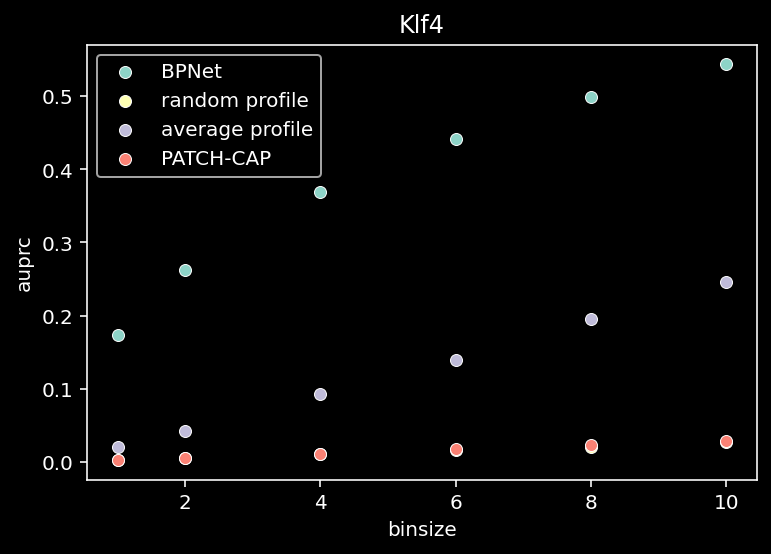
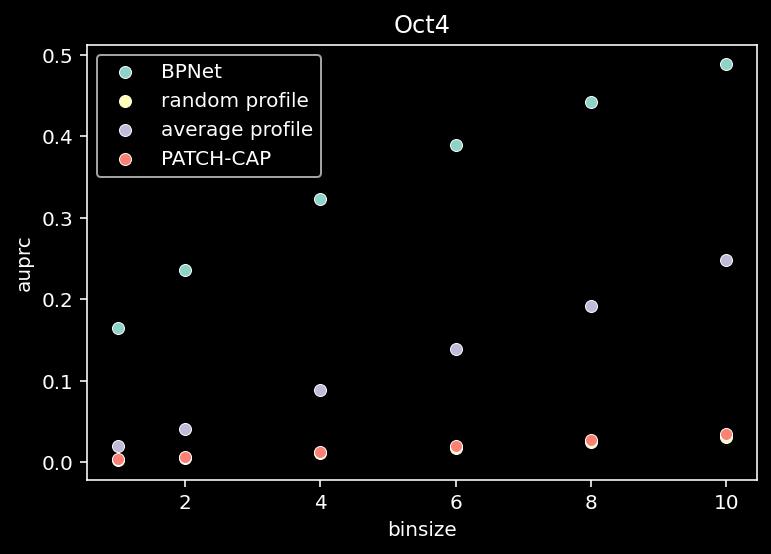
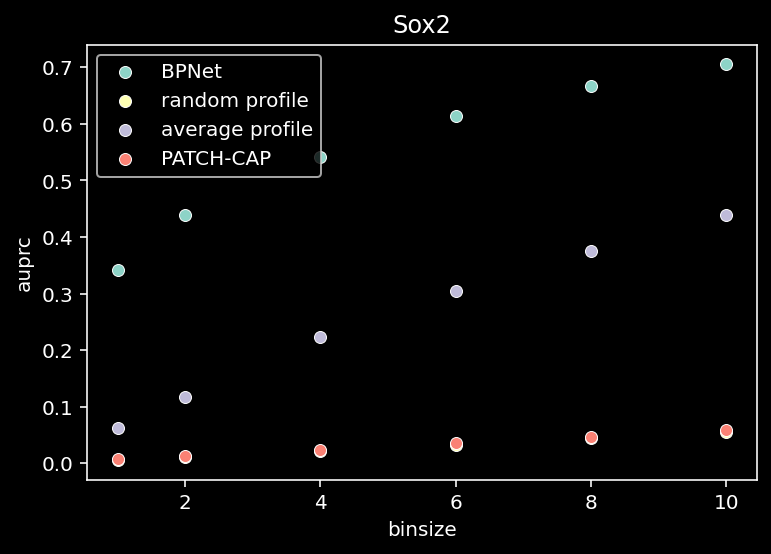
for tf_index, tf in enumerate(TF_LIST):
patchcap_cp = patchcap.copy()
# subset for one tf
pred = all_pred[:, tf_index, :, :]
counts = true_counts[:, tf_index, :, :]
# compute auPRC fro all bins
all = compute_auprc_bins(counts, pred, patchcap_cp, verbose=False)
df = pd.DataFrame(all)
df.to_csv(f"/home/philipp/BPNet/out/binsizes_auprc_{tf}_count_model.csv")
sns.scatterplot(x=df["binsize"], y=df["auprc"], label="BPNet")
sns.scatterplot(x=df["binsize"], y=df["random_auprc"], label="random profile")
sns.scatterplot(x=df["binsize"], y=df["average_auprc"], label="average profile")
sns.scatterplot(x=df["binsize"], y=df["patchcap_auprc"], label="PATCH-CAP")
plt.title(f"{tf}")
plt.legend()
plt.show()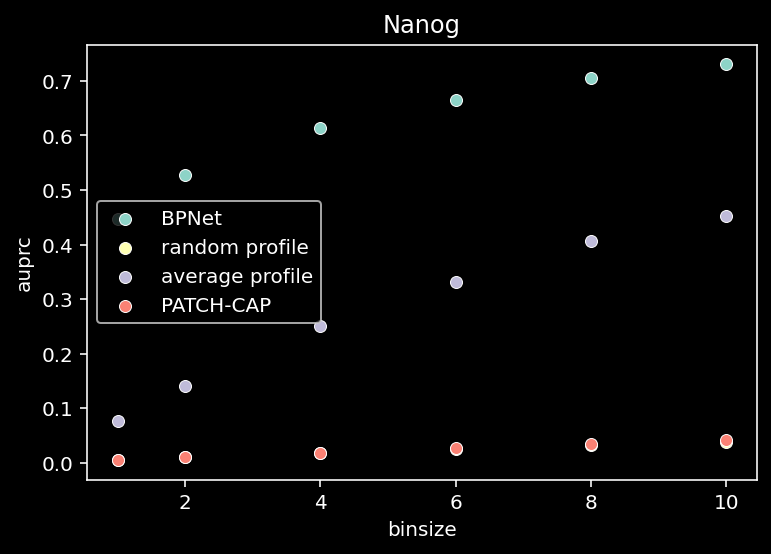
5.4.3 MSE and R2
true_total_counts = test_dataset.tf_counts.sum(axis=-1).copy()
pred_total_counts = test_count_pred.cpu().detach().numpy()
tf_means = true_total_counts.mean(axis=0)
df = pd.DataFrame(columns=["TF", "mse", "tss", "rss", "r2"])
for i, tf in enumerate(TF_LIST):
mse = ((np.log1p(true_total_counts[:, i]) - np.log1p(pred_total_counts[:, i]))**2).mean()
tss = ((true_total_counts[:, i] - tf_means[None, i])**2).sum()
rss = ((true_total_counts[:, i] - pred_total_counts[:, i])**2).sum()
r2 = 1 - rss/tss
tmp_df = pd.DataFrame({"TF": tf, "mse": mse, "tss": tss, "rss": rss, "r2": r2}, index=[0])
df = pd.concat([df, tmp_df], ignore_index=True, axis=0)
df.to_csv("/home/philipp/BPNet/out/count_stats.csv", index=False)